
Many development teams turn to DynamoDB for building event-driven architectures and user-friendly, performant applications at scale. As an operational database, DynamoDB is optimized for real-time transactions even when deployed across multiple geographic locations. However, it does not provide strong performance for search and analytics access patterns.
Search and Analytics on DynamoDB
While NoSQL databases like DynamoDB generally have excellent scaling characteristics, they support only a limited set of operations that are focused on online transaction processing. This makes it difficult to search, filter, aggregate and join data without leaning heavily on efficient indexing strategies.
DynamoDB stores data under the hood by partitioning it over a large number of nodes based on a user-specified partition key field present in each item. This user-specified partition key can be optionally combined with a sort key to represent a primary key. The primary key acts as an index, making query operations inexpensive. A query operation can do equality comparisons (=) on the partition key and comparative operations (>, <, =, BETWEEN) on the sort key if specified.
Performing analytical queries not covered by the above scheme requires the use of a scan operation, which is typically executed by scanning over the entire DynamoDB table in parallel. These scans can be slow and expensive in terms of read throughput because they require a full read of the entire table. Scans also tend to slow down when the table size grows, as there is more data to scan to produce results. If we want to support analytical queries without encountering prohibitive scan costs, we can leverage secondary indexes, which we will discuss next.
Indexing in DynamoDB
In DynamoDB, secondary indexes are often used to improve application performance by indexing fields that are queried frequently. Query operations on secondary indexes can also be used to power specific features through analytic queries that have clearly defined requirements.
Secondary indexes consist of creating partition keys and optional sort keys over fields that we want to query. There are two types of secondary indexes:
-
Local secondary indexes (LSIs): LSIs extend the hash and range key attributes for a single partition.
-
Global secondary indexes (GSIs): GSIs are indexes that are applied to an entire table instead of a single partition.
However, as Nike discovered, overusing GSIs in DynamoDB can be expensive. Analytics in DynamoDB, unless they are used only for very simple point lookups or small range scans, can result in overuse of secondary indexes and high costs.
The costs for provisioned capacity when using indexes can add up quickly because all updates to the base table have to be made in the corresponding GSIs as well. In fact, AWS advises that the provisioned write capacity for a global secondary index should be equal to or greater than the write capacity of the base table to avoid throttling writes to the base table and crippling the application. The cost of provisioned write capacity grows linearly with the number of GSIs configured, making it cost prohibitive to use many GSIs to support many access patterns.
DynamoDB is also not well-designed to index data in nested structures, including arrays and objects. Before indexing the data, users will need to denormalize the data, flattening the nested objects and arrays. This could greatly increase the number of writes and associated costs.
For a more detailed examination of using DynamoDB secondary indexes for analytics, see our blog Secondary Indexes For Analytics On DynamoDB.
The bottom line is that for analytical use cases, you can gain significant performance and cost advantages by syncing the DynamoDB table with a different tool or service that acts as an external secondary index for running complex analytics efficiently.
DynamoDB + Elasticsearch
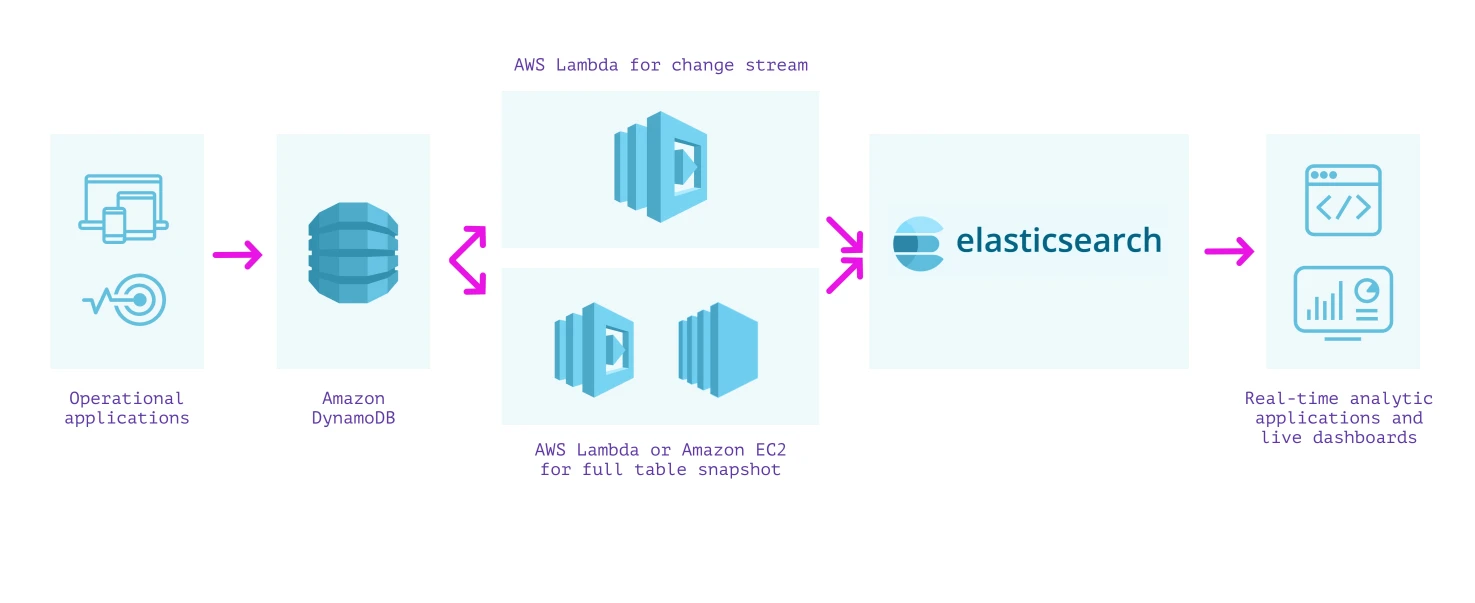
One approach to building a secondary index over our data is to use DynamoDB with Elasticsearch. Cloud-based Elasticsearch, such as Elastic Cloud or Amazon OpenSearch Service, can be used to provision and configure nodes according to the size of the indexes, replication, and other requirements. A managed cluster requires some operations to upgrade, secure, and keep performant, but less so than running it entirely by yourself on EC2 instances.

As the approach using the Logstash Plugin for Amazon DynamoDB is unsupported and rather difficult to set up, we can instead stream writes from DynamoDB into Elasticsearch using DynamoDB Streams and an AWS Lambda function. This approach requires us to perform two separate steps:
- We first create a lambda function that is invoked on the DynamoDB stream to post each update as it occurs in DynamoDB into Elasticsearch.
- We then create a lambda function (or EC2 instance running a script if it will take longer than the lambda execution timeout) to post all the existing contents of DynamoDB into Elasticsearch.
We must write and wire up both of these lambda functions with the correct permissions in order to ensure that we do not miss any writes into our tables. When they are set up along with required monitoring, we can receive documents in Elasticsearch from DynamoDB and can use Elasticsearch to run analytical queries on the data.
The advantage of this approach is that Elasticsearch supports full-text indexing and several types of analytical queries. Elasticsearch supports clients in various languages and tools like Kibana for visualization that can help quickly build dashboards. When a cluster is configured correctly, query latencies can be tuned for fast analytical queries over data flowing into Elasticsearch.
Disadvantages include that the setup and maintenance cost of the solution can be high. Even managed Elasticsearch requires dealing with replication, resharding, index growth, and performance tuning of the underlying instances.
Elasticsearch has a tightly coupled architecture that does not separate compute and storage. This means resources are often overprovisioned because they cannot be independently scaled. In addition, multiple workloads, such as reads and writes, will contend for the same compute resources.
Elasticsearch also cannot handle updates efficiently. Updating any field will trigger a reindexing of the entire document. Elasticsearch documents are immutable, so any update requires a new document to be indexed and the old version marked deleted. This results in additional compute and I/O expended to reindex even the unchanged fields and to write entire documents upon update.
Because lambdas fire when they see an update in the DynamoDB stream, they can have have latency spikes due to cold starts. The setup requires metrics and monitoring to ensure that it is correctly processing events from the DynamoDB stream and able to write into Elasticsearch.
Functionally, in terms of analytical queries, Elasticsearch lacks support for joins, which are useful for complex analytical queries that involve more than one index. Elasticsearch users often have to denormalize data, perform application-side joins, or use nested objects or parent-child relationships to get around this limitation.
Advantages
- Full-text search support
- Support for several types of analytical queries
- Can work over the latest data in DynamoDB
Disadvantages
- Requires management and monitoring of infrastructure for ingesting, indexing, replication, and sharding
- Tightly coupled architecture results in resource overprovisioning and compute contention
- Inefficient updates
- Requires separate system to ensure data integrity and consistency between DynamoDB and Elasticsearch
- No support for joins between different indexes
This approach can work well when implementing full-text search over the data in DynamoDB and dashboards using Kibana. However, the operations required to tune and maintain an Elasticsearch cluster in production, its inefficient use of resources and lack of join capabilities can be challenging.
DynamoDB + Rockset
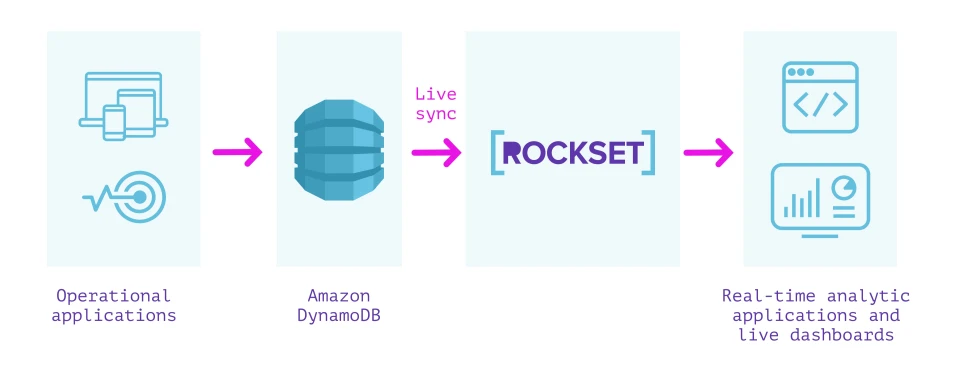
Rockset is a fully managed search and analytics database built primarily to support real-time applications with high QPS requirements. It is often used as an external secondary index for data from OLTP databases.
Rockset has a built-in connector with DynamoDB that can be used to keep data in sync between DynamoDB and Rockset. We can specify the DynamoDB table we want to sync contents from and a Rockset collection that indexes the table. Rockset indexes the contents of the DynamoDB table in a full snapshot and then syncs new changes as they occur. The contents of the Rockset collection are always in sync with the DynamoDB source; no more than a few seconds apart in steady state.
Rockset manages the data integrity and consistency between the DynamoDB table and the Rockset collection automatically by monitoring the state of the stream and providing visibility into the streaming changes from DynamoDB.
Without a schema definition, a Rockset collection can automatically adapt when fields are added/removed, or when the structure/type of the data itself changes in DynamoDB. This is made possible by strong dynamic typing and smart schemas that obviate the need for any additional ETL.
The Rockset collection we sourced from DynamoDB supports SQL for querying and can be easily used by developers without having to learn a domain-specific language. It can also be used to serve queries to applications over a REST API or using client libraries in several programming languages. The superset of ANSI SQL that Rockset supports can work natively on deeply nested JSON arrays and objects, and leverage indexes that are automatically built over all fields, to get millisecond latencies on even complex analytical queries.
Rockset has pioneered compute-compute separation, which allows isolation of workloads in separate compute units while sharing the same underlying real-time data. This offers users greater resource efficiency when supporting simultaneous ingestion and queries or multiple applications on the same data set.
In addition, Rockset takes care of security, encryption of data, and role-based access control for managing access to it. Rockset users can avoid the need for ETL by leveraging ingest transformations we can set up in Rockset to modify the data as it arrives into a collection. Users can also optionally manage the lifecycle of the data by setting up retention policies to automatically purge older data. Both data ingestion and query serving are automatically managed, which lets us focus on building and deploying live dashboards and applications while removing the need for infrastructure management and operations.
Especially relevant in relation to syncing with DynamoDB, Rockset supports in-place field-level updates, so as to avoid costly reindexing. Compare Rockset and Elasticsearch in terms of ingestion, querying and efficiency to choose the right tool for the job.
Summary
- Built to deliver high QPS and serve real-time applications
- Completely serverless. No operations or provisioning of infrastructure or database required
- Compute-compute separation for predictable performance and efficient resource utilization
- Live sync between DynamoDB and the Rockset collection, so that they are never more than a few seconds apart
- Monitoring to ensure consistency between DynamoDB and Rockset
- Automatic indexes built over the data enabling low-latency queries
- In-place updates that avoids expensive reindexing and lowers data latency
- Joins with data from other sources such as Amazon Kinesis, Apache Kafka, Amazon S3, etc.
We can use Rockset for implementing real-time analytics over the data in DynamoDB without any operational, scaling, or maintenance concerns. This can significantly speed up the development of real-time applications. If you'd like to build your application on DynamoDB data using Rockset, you can get started for free on here.