
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Muhammed Yusuf Kocyigit, Boston University;
(2) Anietie Andy, University of Pennsylvania;
(3) Derry Wijaya, Boston University.
Table of Links
- Abstract and Intro
- Related Works
- Data
- Method
- Analysis and Results
- Conclusion
- Limitations
- Ethics Statement and References
- Appendix: Toxicity Measurement
- Appendix: Correlation Over Time
- Appendix: Wikidata
- Appendix: Hyperparameter Sensitivity
Abstract
Long-term exposure to biased content in literature or media can significantly influence people’s perceptions of reality, leading to the development of implicit biases that are difficult to detect and address (Gerbner 1998). In this study, we propose a novel method to analyze the differences in representation between two groups and use it examine the representation of African Americans and White Americans in books between 1850 to 2000 with the Google Books dataset (Goldberg and Orwant 2013). By developing better tools to understand differences in representation, we aim to contribute to the ongoing efforts to recognize and mitigate biases. To improve upon the more common phrase-based (men, women, white, black, etc) methods to differentiate context (Tripodi et al. 2019; Lucy, Tadimeti, and Bamman 2022), we propose collecting a comprehensive list of historically significant figures and using their names to select relevant context. This novel approach offers a more accurate and nuanced method for detecting implicit biases through reducing the risk of selection bias. We create group representations for each decade and analyze them in an aligned semantic space (Hamilton, Leskovec, and Jurafsky 2016). We further support our results by assessing the time-adjusted toxicity (Bassignana, Basile, and Patti 2018) in the context for each group and identifying the semantic axes (Lucy, Tadimeti, and Bamman 2022) that exhibit the most significant differences between the groups across decades. We support our method by showing that our proposed method can capture known socio-political changes accurately and our findings indicate that while the relative number of African American names mentioned in books have increased over time, the context surrounding them remains more toxic than white Americans.
Introduction
In the last two hundred years, perhaps with the exception of the last decade, books have been one of the most important medium for the dissemination and perpetuation of knowledge and culture across generations.
Analyzing the content of books through time resembles examining the rings in the cross section of a tree. It can tell us about the past and help us understand the present. By studying how different groups of people are portrayed in books throughout history, we aim to better understand the ways in which racial bias has manifested and developed through time.
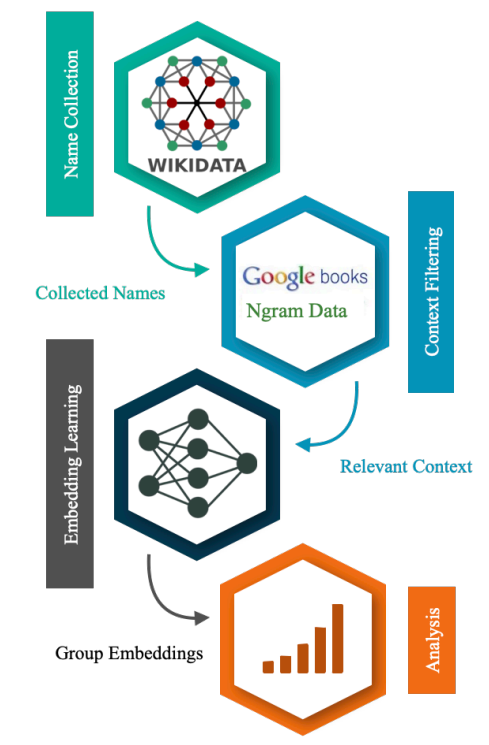
Recent advances in text representation and content analysis has enabled us to process large corpora and create meaningful representations that we can analyze, enabling large scale, longitudinal text based studies. In this work we aim to integrate and enhance a diverse array of methods to create a toolbox for analyzing such content.
Our method[1] as summarized in Figure 1 consists of 4 stages. First we collect a large sample of individuals that represent the groups we will analyze. In our case we want to examine the context surrounding African-Americans and White Americans in books published in the United States between 1850-2000. So we collect the name and ethnicity of every person who has lived in the United States from Wikipedia. Then we take the Google Books dataset and filter the n-grams that contain any of the names that we have collected. We use these n-grams to train embeddings that represent each ethnic group and finally use these embeddings to study the differences in the context in which each group is talked about and how it has changed over 15 decades. The longitudinal nature is a vital aspect of this study as it allows us to study biases that are cultivated through extended exposure. These biases can affect the base frame that people ground their notion of normalcy in. Thus, understanding them presents a critical issue since gaining awareness of one’s sense of normalcy is a challenging task without the aid of explicit external information and intentional inquiry.
While similar work exists at the intersection of Natural Language Processing and social sciences, our work has some important differences. Researchers have used word representations in combination with other text processing tools to represent changes in the meanings of words (Martinc, Kralj Novak, and Pollak 2020), analyze online communities to detect gender bias (Lucy, Tadimeti, and Bamman 2022), analyze literary work to detect racial bias (Tripodi et al. 2019), or quantify ethnic stereotypes in the news (Sorato, Zavala-Rojas, and del Carme Colominas Ventura 2021). However, these methods predominantly use referring words (woman, man, African American, Jewish, etc.) or gendered terms (he, she, lady, gentleman, etc.) to differentiate each group’s context.
Instead of referring phrases, in this work, we directly employ a list of names of African American and White American figures (politician, athlete, musician, and social leader categories) for each decade from Wikipedia. While any representation method has downsides, we propose that this personal-based representation may better capture implicit biases such as coded language (covert expression of racism that avoids any mention of race)[2] particularly as names do not have explicit references to a larger group. Although individuals may possess knowledge of the race of the person they are writing about, the statements they make are not inherently generalizations. As a result, authors may express their implicit biases openly in their writing. Consequently, if we analyze a substantial corpus of text and find that these instances of bias occur frequently, we can identify a systematic pattern of implicit bias. Hence, we use how individuals from a racial group are presented to analyze biases for the general group. In addition, investigating personal-based racial bias holds significance as studies have shown its association with more detrimental effects on mental health than group-level bias (Hagiwara, Alderson, and Mezuk 2016).
Additionally our proposed method gets around the problem of selecting referring phrases. Selecting unbiased, phrases that will return a large enough context for analysis becomes a challenge, if not a roadblock since social-context itself is ever changing and the tools for referring change as well. We present the number of words returned from the complete Google n-grams data with the referring phraseand person-based filtering methods for 15 decades in Figure 2. The number of n-grams containing referring phrases for the decades before 1970 is around 10K, which is too few considering these n-grams contain a lot of stop words and part-of-speech tags.
Similar to (Lucy, Tadimeti, and Bamman 2022) we use learned group representations as our unit of analysis. Unlike previous work, we propose using a contrastive objective to learn the representations to better capture implicit biases since the absence of a positive context should be just as strong a signal toward bias as the existence of a negative one. Due to its subtle language, implicit biases may be hard to identify when doing a one-sided analysis alone but may be visible when we look at the differences in the context used when referring to people from different racial groups. Contrastive learning allows us to represent positive and negative distributional differences in the context of two groups.
Additionally, we enhance our analysis by analyzing multiple aspects of the text surrounding each group. We look at the frequency of toxic words in each decade per racial group. We also employ semantic axes (Lucy, Tadimeti, and Bamman 2022) to analyze the difference in the embeddings of the racial groups with respect to a variety of semantic axes and how this changes over the 15 decades.
In summary, our contributions in this work are:
• We propose a novel method of analyzing bias between two groups with person-based filtering that is based on the names of people in a group instead of referringphrases or group terms.
• We use contrastive learning to capture both the presence and absence of relevant information to better represent the difference in context.
• We conduct, to the best of our knowledge, the first largescale longitudinal study of the bias between AfricanAmericans and White Americans in books published in the United States between 1850-2000.
• We orchestrate multiple analysis methods and integrate them with our representation learning method, showing easy integration of our representation learning method with existing literature. In our integration, we also take into account the semantic changes that occur through long time periods.
[1] We will release the data and code to encourage further development and application of our method.
[2] https://www.r2hub.org/library/overt-and-covert-racism