
Authors:
(1) Mingjie Liu, NVIDIA {Equal contribution};
(2) Teodor-Dumitru Ene, NVIDIA {Equal contribution};
(3) Robert Kirby, NVIDIA {Equal contribution};
(4) Chris Cheng, NVIDIA {Equal contribution};
(5) Nathaniel Pinckney, NVIDIA {Equal contribution};
(6) Rongjian Liang, NVIDIA {Equal contribution};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Table of Links
- Abstract and Intro
- Dataset
- ChipNemo Domain Adaptation Methods
- LLM Applications
- Evaluations
- Discussion
- Related Works
- Conclusions
- Acknowledgments, Contributions and References
- Appendix
III. CHIPNEMO DOMAIN ADAPTATION METHODS
ChipNeMo implements multiple domain adaptation techniques to adapt LLMs to the chip design domain. These techniques include custom tokenizers for chip design data, domain adaptive pretraining with large corpus of domain data, supervised-fine-tuning with domain specific tasks, and retrievalaugmented generation with a fine-tuned retrieval model. We will illustrate the details of each technique in this section.
A. Tokenizer
When adapting a pre-trained tokenizer, the main goals are to improve tokenization efficiency on domain-specific data, maintain efficiency and language model performance on general datasets, and minimize the effort for retraining/fine-tuning. To achieve this, we’ve developed a four-step approach:
• Step 1: Training a tokenizer from scratch using domain specific data.
• Step 2: From the vocabulary of the new tokenizer, identifying tokens that are absent in the general-purpose tokenizer and are rarely found in general-purpose datasets.
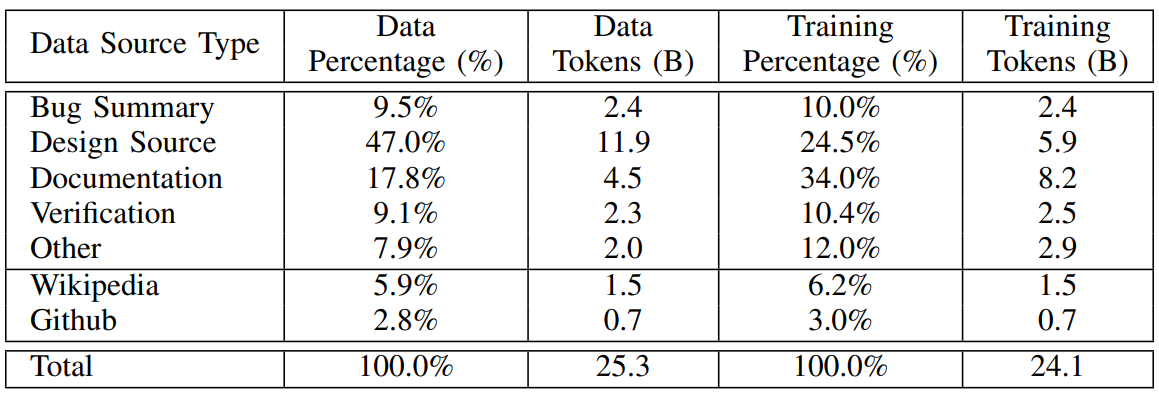

• Step 3: Expanding the general-purpose tokenizer with the newly identified tokens at Step 2.
• Step 4: Initializing the embeddings of the new tokens by utilizing the general-purpose tokenizer.
Specifically for Step 4, when a new token is encountered, it is tokenized using the pretrained general-purpose tokenizer. The embedding of the new token is determined by averaging the embeddings of the tokens generated by the general-purpose tokenizer [24], and the output layer weights initialized to zero.
Step 2 helps maintain the performance of the pre-trained LLM on general datasets by selectively introducing new tokens that are infrequently encountered in general-purpose datasets. And Step 4 reduces the effort required for retraining/finetuning the LLM via initialization of the embeddings of new tokens guided by the general-purpose tokenizer.
B. Domain Adaptive Pretraining
In our study, we apply DAPT on pretrained foundation base models LLaMA2 7B/13B. Each DAPT model is initialized using the weights of their corresponding pretrained foundational base models. We name our DAPT models ChipNeMo. We employ tokenizer augmentation as depicted in Section III-A and initialize embedding weight accordingly [24]. We conduct further pretraining on domain-specific data by employing the standard autoregressive language modeling objective. All model training procedures are conducted using the NVIDIA NeMo framework [25], incorporating techniques such as tensor parallelism [26] and flash attention [27] for enhanced efficiency.

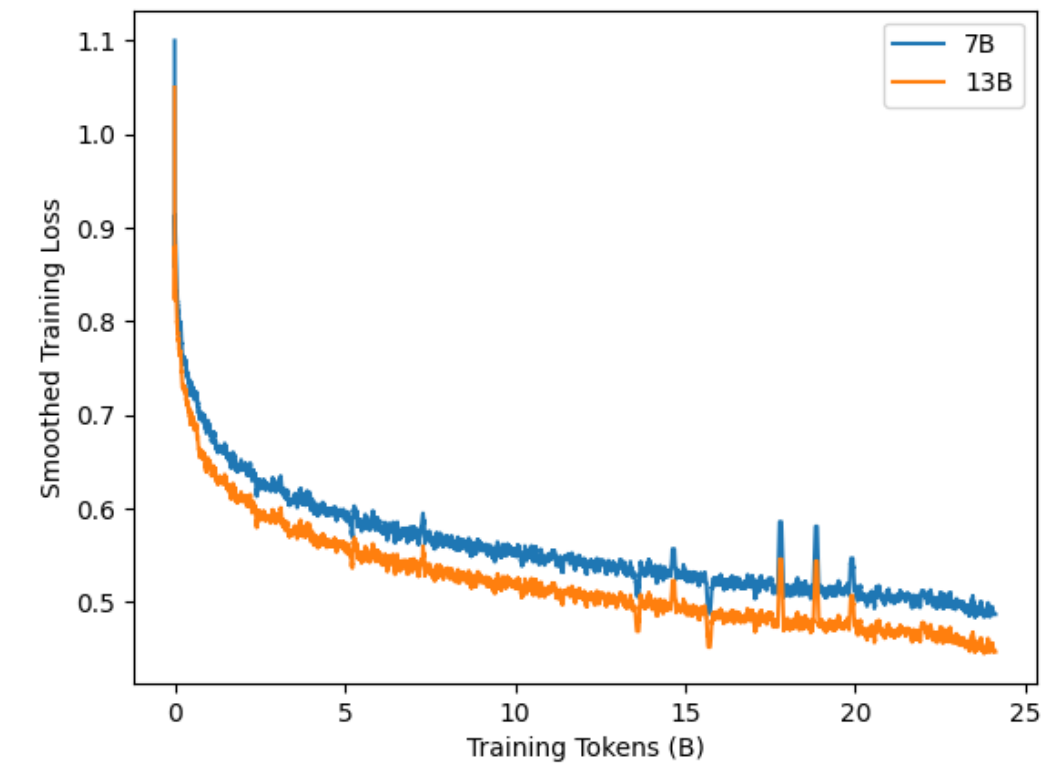
Figure 2 illustrates the training loss of ChipNeMo under the specified hyperparameters. We do observe spikes in the training loss. In contrast to the hypothesis in [28], we postulate that in our scenario, these spikes can be attributed to “bad data” since these irregularities seem to consistently occur in similar training steps for the same model, even across different model sizes. We chose not to address this issue, as these anomalies did not appear to significantly impede subsequent training steps (with no noticeable degradation in validation loss), possibly due to our application of a low learning rate.
C. Supervised Fine-Tuning
After DAPT, we perform model alignment with supervised fine-tuning (SFT). We adopt the identical hyperparameter training configuration as DAPT for all models, with the exception of using a reduced global batch size of 128. All SFT data is structured according to the chat template below:
<extra_id_0>system\n{system}
<extra_id_1>User\n{user_utterance}
<extra_id_1>Assistant\n{chipnemo_response}
…
We employ an autoregressive optimization objective, implementing a strategy where losses associated with tokens originating from the system and user prompts are masked [5]. This approach ensures that during backpropagation, our focus is exclusively directed towards the optimization of answer tokens.
We combine our domain SFT dataset, comprising approximately 1.1k samples, with the more extensive general chat SFT dataset of 128k samples. We then engaged in fine-tuning for a single epoch after applying a random shuffle to the data. We conducted experiments involving augmentation of the domain-specific SFT dataset for more than one epoch. However, it became evident that the model rapidly exhibited signs of overfitting when presented with in-domain questions, often repeating irrelevant answers from the domain SFT dataset.
Additionally, we conducted an additional SFT using solely the general chat dataset, excluding any domain-specific SFT data. For clarity, we designate all our ChipNeMo models as follows:
-
ChipNeMo-Chat: Models fine-tuned with both domain and general chat data;
-
ChipNeMo-Chat (noDSFT): Models fine-tuned with general chat data exclusively.
We also experimented with DAPT directly on a chat aligned model, such as the LLaMA2-Chat model. We found that DAPT significantly degraded the model’s alignment, making the resulting model useless for downstream tasks.
D. Retrieval-Augmented Generation
It is well known that LLMs can generate inaccurate text, so-called hallucination [29]. Although the phenomenon is not completely understood, we still must mitigate hallucinations since they are particularly problematic in an engineering assistant chatbot context, where accuracy is critical. Our proposal is to leverage the retrieval augmented generation (RAG) method. RAG tries to retrieve relevant passages from a database to be included in the prompt together with the question, which grounds the LLM to produce more accurate answers. We find that using a domain adapted language model for RAG significantly improves answer quality on our domain specific questions. Also, we find that fine-tuning an off-the-shelf unsupervised pre-trained dense retrieval model with a modest amount of domain specific training data significantly improves retrieval accuracy. Our domain-adapted RAG implementation diagram is illustrated on Figure 3.
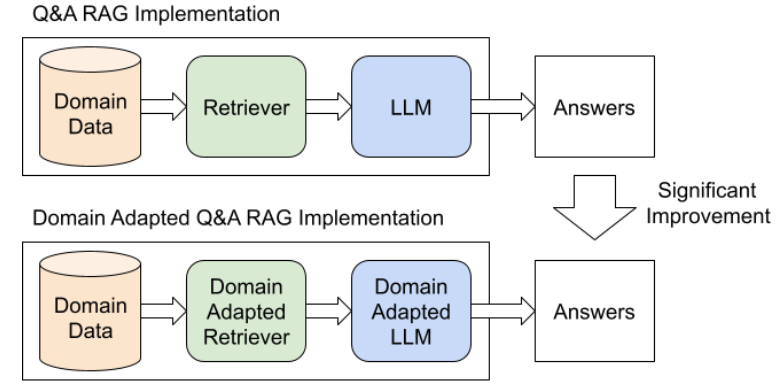
We created our domain adapted retrieval model by fine-tuning the e5_small_unsupervised model [30] with 3000 domain specific auto-generated samples using the Tevatron framework [31]. The sample generation and training process are covered in Appendix C.
Even with the significant gains that come with fine-tuning a retrieval model, the fact remains that retrieval still struggles with queries that do not map directly to passages in the document corpus or require more context not present in the passage. Unfortunately, these queries are also more representative of queries that will be asked by engineers in real situations. Combining retrieval with a domain adapted language model is one way to address this issue.
This paper is available on arxiv under CC 4.0 license.