
Authors:
(1) Pinelopi Papalampidi, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh;
(2) Frank Keller, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh;
(3) Mirella Lapata, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh.
Table of Links
- Abstract and Intro
- Related Work
- Problem Formulation
- Experimental Setup
- Results and Analysis
- Conclusions and References
- A. Model Details
- B. Implementation Details
- C. Results: Ablation Studies
Abstract
Movie trailers perform multiple functions: they introduce viewers to the story, convey the mood and artistic style of the film, and encourage audiences to see the movie. These diverse functions make automatic trailer generation a challenging endeavor. We decompose it into two subtasks: narrative structure identification and sentiment prediction. We model movies as graphs, where nodes are shots and edges denote semantic relations between them. We learn these relations using joint contrastive training which leverages privileged textual information (e.g., characters, actions, situations) from screenplays. An unsupervised algorithm then traverses the graph and generates trailers that human judges prefer to ones generated by competitive supervised approaches.
1. Introduction
Trailers are short videos used for promoting movies and are often critical to commercial success. While their core function is to market the film to a range of audiences, trailers are also a form of persuasive art and promotional narrative, designed to make viewers want to see the movie. Even though the making of trailers is considered an artistic endeavor, the film industry has developed strategies guiding trailer construction. According to one school of thought, trailers must exhibit a narrative structure, consisting of three acts[1]. The first act establishes the characters and setup of the story, the second act introduces the main conflict, and the third act raises the stakes and provides teasers from the ending. Another school of thought is more concerned with the mood of the trailer as defined by the ups and downs of the story[2]. According to this approach, trailers should have medium intensity at first in order to captivate viewers, followed by low intensity for delivering key information about the story, and then progressively increasing intensity until reaching a climax at the end of the trailer.
To create trailers automatically, we need to perform lowlevel tasks such as person identification, action recognition, and sentiment prediction, but also more high-level ones such as understanding connections between events and their causality, as well as drawing inferences about the characters and their actions. Given the complexity of the task, directly learning all this knowledge from movie-trailer pairs would require many thousands of examples, whose processing and annotation would be a challenge. It is thus not surprising that previous approaches to automatic trailer generation [24,46,53] have solely focused on audiovisual features.
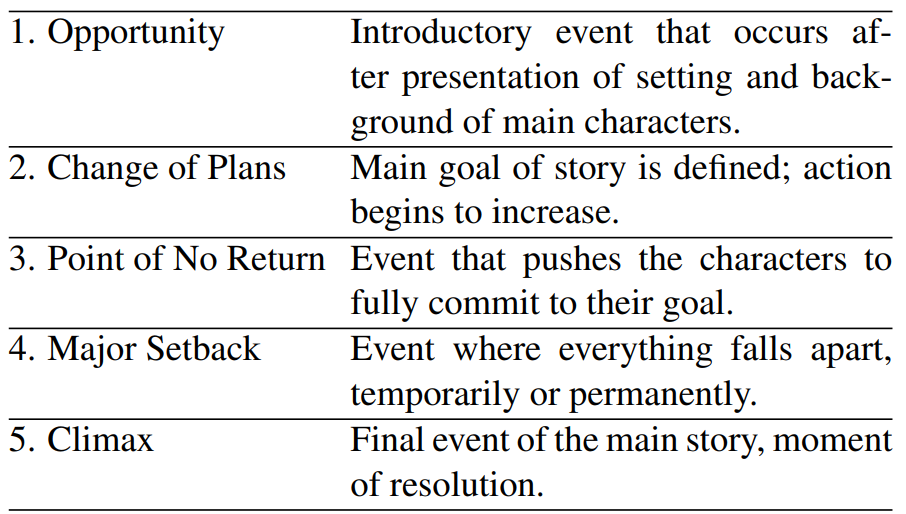
Inspired by the creative process of human editors, we adopt a bottom-up approach to trailer generation, which we decompose into two orthogonal, simpler and well-defined subtasks. The first is the identification of narrative structure, i.e., retrieving the most important events of the movie. A commonly adopted theory in screenwriting [13,22,51] suggests that there are five types of key events in a movie’s plot, known as turning points (TPs; see their definitions in Figure 1). The second subtask is sentiment prediction, which we view as an approximation of flow of intensity between shots and the emotions evoked.
We generate proposal trailers following an unsupervised graph-based approach. We model movies as graphs whose nodes are shots and whose edges denote important semantic connections between shots (see Figure 2). In addition, nodes bear labels denoting whether they are key events (i.e., TPs) and scores signaling sentiment intensity (positive or negative). Our algorithm traverses this movie graph to create trailer sequences. These could be used as proposals to be reviewed and modified by a human editor.
Both the tasks of TP identification and sentiment prediction stand to benefit from a lower-level understanding of movie content. Indeed, we could employ off-theshelf modules for identifying characters and places, recognizing actions, and localizing semantic units. However, such approaches substantially increase pre-processing time and memory requirements during training and inference and suffer from error propagation. Instead, we propose a contrastive learning regime, where we take advantage of screenplays as privileged information, i.e., information available at training time only. Screenplays reveal how the movie is segmented into scenes, who the characters are, when and who they are speaking to, where they are and what they are doing (i.e., “scene headings” explain where the action takes place while “action lines” describe what the camera sees). Specifically, we build two individual networks, a textual network based on screenplays and a multimodal one based on video, and train them jointly using auxiliary contrastive losses. The textual network can additionally be pretrained on large collections of screenplays via self-supervised learning, without having to collect and process the corresponding movies. Experimental results show that this contrastive training approach is beneficial, leading to trailers which are judged favorably by humans in terms of their content and attractiveness.
This paper is available on arxiv under CC BY-SA 4.0 DEED license.
[1] https://www.studiobinder.com/blog/how-to-make-a-movie-trailer
[2] https://www.derek-lieu.com/blog/2017/9/10/the-matrix-is-a-trailereditors-dream