Authors:
(1) Jingjing Wang, School of Computing Clemson University Clemson, South Carolina, USA;
(2) Joshua Luo, The Westminster Schools Atlanta, Georgia, USA;
(3) Grace Yang, South Windsor High School South Windsor, Connecticut, USA;
(4) Allen Hong, D.W. Daniel High School Clemson, South Carolina, USA;
(5) Feng Luo, School of Computing Clemson University Clemson, South Carolina, USA.
Table of Links
III. METHODOLOGY
A. Dataset details
In our experimental design, we focused on two distinct datasets for sentiment analysis: the Facebook Hateful Memes dataset, and the Multimodal Memotion Analysis dataset. Each of these datasets brought unique elements to our study, enabling a multifaceted exploration of GPT’s capabilities in multimodal reasoning tasks.
The Facebook Hateful Memes dataset was created with the primary intent of observing and understanding the influence of memes in propagating hate speech and offensive content. We randomly chose 200 memes from the Facebook Hateful Meme dataset for our experiments: a set of 100 randomly chosen hateful memes and the other set of 100 non-hateful memes. The primary criteria for this categorization were based on the content and contextual implications of the text interwoven within these meme images. This subset is teeming with complex emotions, often characterized by layers of sarcasm or satire. This provides an exceptionally challenging yet rewarding terrain for testing the proficiency of our approach in deciphering and correctly classifying the sentiments embedded within these memes.
The Multimodal Memotion Analysis dataset, on the other hand, is a more diverse collection of memes. We randomly selected 100 memes from this dataset, spanning a wide range of sentiments. This dataset is designed to assess the ability of the AI model to deal with a broader scope of emotions and sentiments. The memes in this dataset cover a variety of themes and concepts. They contain different types of memes, each conveying a unique sentiment. These sentiments covered range from clear-cut positive or negative overall sentiment to more complex emotions like humor, which type includes humorous, sarcastic and offensive. Furthermore, the scale is introduced to evaluate the degree of humor, where ”not” corresponds to 0, ”slightly” to 1, ”mildly” to 2, and ”very” to 3 (see Fig. 2). The broad spectrum of sentiments present in this dataset poses a significant challenge to the AI model, demanding a high degree of understanding and reasoning capability.
B. Experimental Setup and Workflow
The main objective of the experimental setup was to configure GPT to process multimodal tasks, particularly those associated with visual content. As GPT-3.5 lacks the ability to process images, we supplemented it with the image processing capabilities of VisualGPT, which allowed GPT to ’see’ the images and generate a description of each image’s visual content.
To guide the model’s reasoning process, we used the TaskMatrix template, a tool developed by Microsoft. The TaskMatrix enabled us to construct a sequence of tasks for GPT that required it to draw upon and exercise its multimodal reasoning skills.
The experimental workflow was divided into several phases:
Image Processing Phase: The image processing phase was the initial stage of the procedure. The image analysis capabilities of VisualGPT were used to analyze the images from the datasets during this phase. VisualGPT was used to build a descriptive representation of the picture’s content for each image. The description was then fed into GPT, allowing it to ’see’ the image. This procedure effectively endowed GPT with the capability to ’understand’ the visual content in the images, an essential prerequisite for performing sentiment analysis on these images;
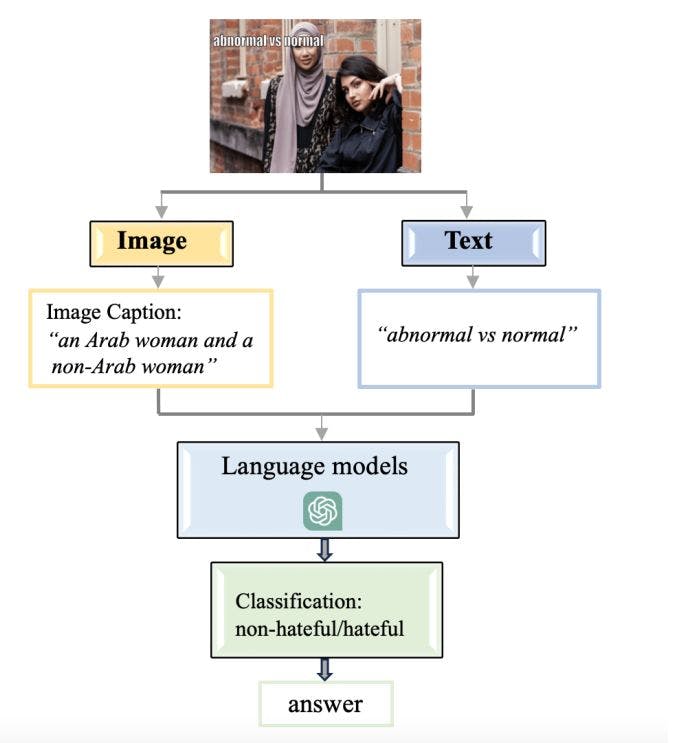
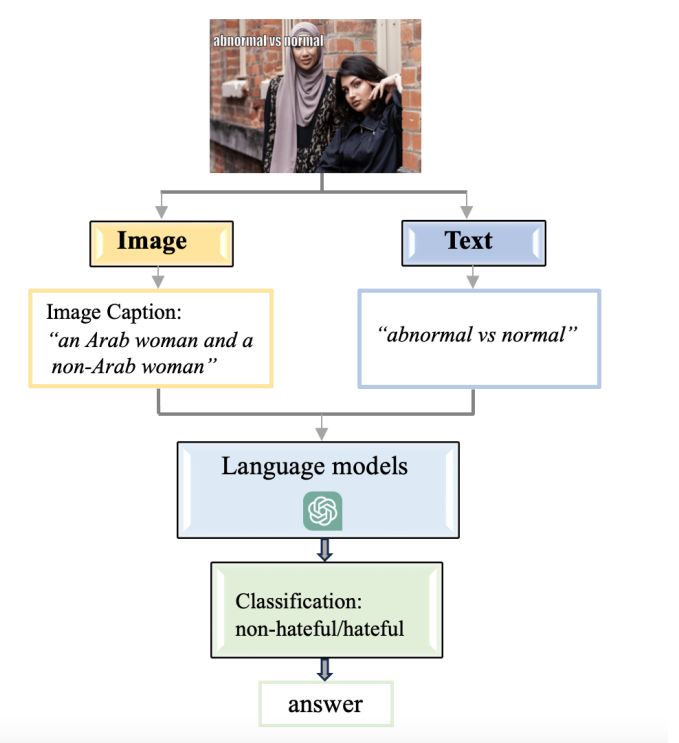
Sentiment Analysis Phase: Upon receiving the image descriptions from VisualGPT, the next stage was to utilize these descriptions to conduct sentiment analysis. For the Facebook hateful memes dataset, we employed a pre-defined notion of ’hateful sentiment’. We tasked GPT with determining if the sentiment associated with each image, as conveyed through the image’s description, was hateful or non-hateful (see Fig. 3 as illustration). For the Google memotion dataset, GPT was asked to provide a generalized assessment of whether the overall sentiment of the image was positive or negative. In addition, we asked GPT to give us a detailed rating of each image in certain categories like humor, sarcasm, and offensiveness. The model was directed to rate the images in these categories on a scale from 0 to 3 (see Fig. 4 as illustration);
Data Storage Phase: Once the model’s responses were obtained, they were collected and organized in the data storage phase. The results corresponding to each image, including the image’s original sentiment label and GPT’s sentiment assessment, were recorded and stored in a csv file. This file was then used for the subsequent analysis of the model’s performance;
Accuracy Analysis Phase: The final phase of the experimental workflow was the accuracy analysis phase. In this phase, a specially developed program compared GPT’s sentiment assessments with the original sentiment labels of the images to evaluate the model’s accuracy. The accuracy was quantified as the proportion of images for which GPT’s sentiment assessment matched the original sentiment label.
This paper is available on arxiv under CC 4.0 license.