
-
Extracting the text from the original documents (HTML, PDF, Markdown, etc.).
-
Chunking the text to specific sizes based on document structure and semantics.
-
Storing chunks in a vector database keyed by an embedding of the chunk.
-
Retrieving the chunks relevant to a question for use as a context when generating the answer.
However, RAG based on vector similarity has a few weaknesses. Since it focuses on information similar to the question, it is harder to answer questions involving multiple topics and/or requiring multiple hops – for instance. Additionally, it limits the number of chunks retrieved.
Each chunk comes from a distinct source, so in cases where largely similar information exists in multiple places, it needs to choose between retrieving multiple copies of the information (and possibly missing out on other information) or picking only one copy in order to get more different chunks, which then misses out on the nuances of the other sources.
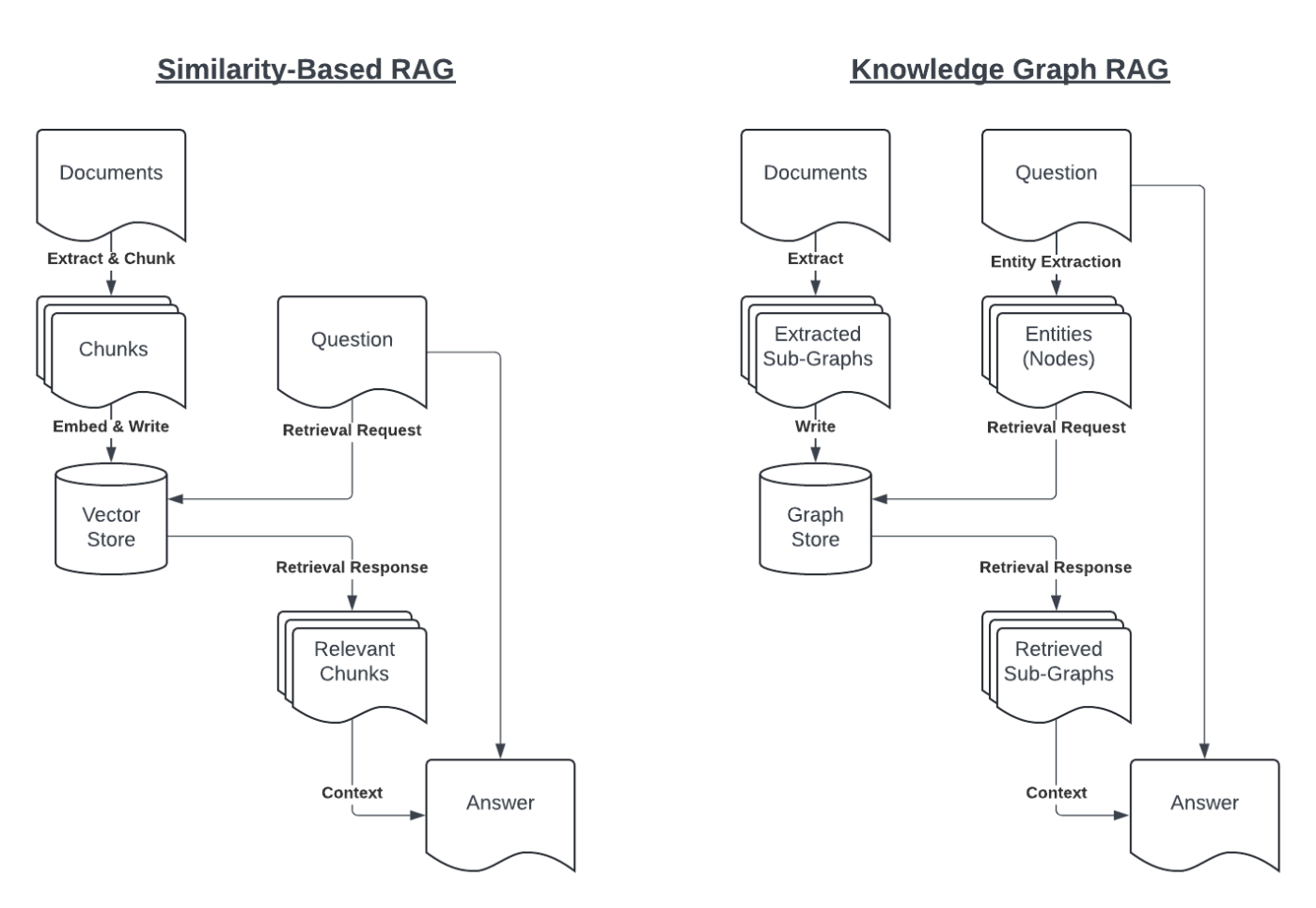
This approach has several benefits over the similarity-based approach:
-
Many facts may be extracted from a single source and associated with a variety of entities within the knowledge graph. This allows for the retrieval of just the relevant facts from a given source rather than the whole chunk, including irrelevant information.
-
If multiple sources say the same thing, they produce the same node or edge. Instead of treating these as distinct facts (and retrieving multiple copies), they can be treated as the same node or edge and retrieved only once. This enables retrieving a wider variety of facts and/or focusing only on facts that appear in multiple sources.
-
The graph may be traversed through multiple steps – not just retrieving information directly related to the entities in the question, but also pulling back things that are 2 or 3 steps away. In a conventional RAG approach, this would require multiple rounds of querying.
In addition to the benefits of using a knowledge graph for RAG, LLMs have also made it easier to create knowledge graphs. Rather than requiring subject matter experts to carefully craft the knowledge graph, an LLM and a prompt can be used to extract information from documents.
This post explores the use of knowledge graphs for RAG, using
We’ll then create LangChain runnables for extracting entities from the question and retrieving the relevant sub-graphs. We’ll see that the operations necessary to implement RAG using knowledge graphs do not require graph databases or graph query languages, allowing the approach to be applied using a typical data store that you may already be using.
Knowledge Graph
As mentioned earlier, a knowledge graph represents distinct entities as nodes. For example, a node may represent “Marie Curie” the person, or “French” the language. In LangChain, each node has a name and a type. We’ll consider both when uniquely identifying a node, to distinguish “French” the language from “French” the nationality.
Relationships between entities correspond to the edges in the graph. Each edge includes the source (for example, Marie Curie the person), the target (Nobel Prize the award), and a type, indicating how the source relates to the target (for example, “won”).
An example knowledge graph extracted from a paragraph about Marie Curie using LangChain is shown below:

Depending on your goals, you may choose to add properties to nodes and edges. For example, you could use a property to identify when the Nobel Prize was won and the category. These can be useful to filter out edges and nodes when traversing the graph during retrieval.
Extraction: Creating the Knowledge Graph
The entities and relationships comprising the knowledge graph can be created directly or imported from existing known-good data sources. This is useful when you wish to curate the knowledge carefully, but it makes it difficult to incorporate new information quickly or handle large amounts of information.
Luckily, LLMs make it easy to extract information from content, so we can use them for extracting the knowledge graph.
Below, I use the
LangChain supports other options such as
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
# Prompt used by LLMGraphTransformer is tuned for Gpt4.
llm = ChatOpenAI(temperature=0, model_name="gpt-4")
llm_transformer = LLMGraphTransformer(llm=llm)
text = """
Marie Curie, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.
She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.
Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.
She was, in 1906, the first woman to become a professor at the University of Paris.
"""
documents = [Document(page_content=text)]
graph_documents = llm_transformer.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents[0].nodes}")
print(f"Relationships:{graph_documents[0].relationships}")
This shows how to extract a knowledge graph using LangChain’s LLMGraphTransformer. You can use the render_graph_document found in the repository to render a LangChain GraphDocument for visual inspection.
In a future post, we’ll discuss how you can examine the knowledge graph both in its entirety as well as the sub-graph extracted from each document and how you can apply prompt engineering and knowledge engineering to improve the automated extraction.
Retrieval: Answering With the Sub-Knowledge Graph
Answering questions using the knowledge graph requires several steps. We first identify where to start our traversal of the knowledge graph. For this example, I’ll prompt an LLM to extract entities from the question. Then, the knowledge graph is traversed to retrieve all relationships within a given distance of those starting points. The default traversal depth is 3. The retrieved relationships and the original question are used to create a prompt and context for the LLM to answer the question.
Extracting Entities From the Question
As with the extraction of the knowledge graph, extracting the entities in a question can be done using a special model or an LLM with a specific prompt. For simplicity, we’ll use an LLM with the following prompt which includes both the question and information about the format to extract. We use a Pydantic model with the name and type to get the proper structure.
QUERY_ENTITY_EXTRACT_PROMPT = (
"A question is provided below. Given the question, extract up to 5 "
"entity names and types from the text. Focus on extracting the key entities "
"that we can use to best lookup answers to the question. Avoid stopwords.\n"
"---------------------\n"
"{question}\n"
"---------------------\n"
"{format_instructions}\n"
)
def extract_entities(llm):
prompt = ChatPromptTemplate.from_messages([keyword_extraction_prompt])
class SimpleNode(BaseModel):
"""Represents a node in a graph with associated properties."""
id: str = Field(description="Name or human-readable unique identifier.")
type: str = optional_enum_field(node_types,
description="The type or label of the node.")
class SimpleNodeList(BaseModel):
"""Represents a list of simple nodes."""
nodes: List[SimpleNode]
output_parser = JsonOutputParser(pydantic_object=SimpleNodeList)
return (
RunnablePassthrough.assign(
format_instructions=lambda _: output_parser.get_format_instructions(),
)
| ChatPromptTemplate.from_messages([QUERY_ENTITY_EXTRACT_PROMPT])
| llm
| output_parser
| RunnableLambda(
lambda node_list: [(n["id"], n["type"]) for n in node_list["nodes"]])
)
Running the above example we can see the entities extracted:
# Example showing extracted entities (nodes)
extract_entities(llm).invoke({ "question": "Who is Marie Curie?"})
# Output:
[Marie Curie(Person)]
Of course, a LangChain Runnable can be used in a chain to extract the entities from a question.
In the future, we’ll discuss ways to improve entity extraction, such as considering node properties or using vector embeddings and similarity search to identify relevant starting points. To keep this first post simple, we’ll stick with the above prompt, and move on to traversing the knowledge graph to retrieve the knowledge-subgraph and include that as the context in the prompt.
Retrieving the Sub-Knowledge Graph
The previous chain gives us the nodes in question. We can use those entities and the graph store to retrieve the relevant knowledge triples. As with RAG, we drop them into the prompt as part of the context and generate answers.
def _combine_relations(relations):
return "\n".join(map(repr, relations))
ANSWER_PROMPT = (
"The original question is given below."
"This question has been used to retrieve information from a knowledge graph."
"The matching triples are shown below."
"Use the information in the triples to answer the original question.\n\n"
"Original Question: {question}\n\n"
"Knowledge Graph Triples:\n{context}\n\n"
"Response:"
)
chain = (
{ "question": RunnablePassthrough() }
# extract_entities is provided by the Cassandra knowledge graph library
# and extracts entitise as shown above.
| RunnablePassthrough.assign(entities = extract_entities(llm))
| RunnablePassthrough.assign(
# graph_store.as_runnable() is provided by the CassandraGraphStore
# and takes one or more entities and retrieves the relevant sub-graph(s).
triples = itemgetter("entities") | graph_store.as_runnable())
| RunnablePassthrough.assign(
context = itemgetter("triples") | RunnableLambda(_combine_relations))
| ChatPromptTemplate.from_messages([ANSWER_PROMPT])
| llm
)
The above chain can be executed to answer a question. For example:
chain.invoke("Who is Marie Curie?")
# Output
AIMessage(
content="Marie Curie is a Polish and French chemist, physicist, and professor who "
"researched radioactivity. She was married to Pierre Curie and has worked at "
"the University of Paris. She is also a recipient of the Nobel Prize.",
response_metadata={
'token_usage': {'completion_tokens': 47, 'prompt_tokens': 213, 'total_tokens': 260},
'model_name': 'gpt-4',
...
}
)
Traverse, Don’t Query
While it may seem intuitive to use a graph DB to store the knowledge graph, it isn’t actually necessary. Retrieving the sub-knowledge graph around a few nodes is a simple graph traversal, while graph DBs are designed for much more complex queries searching for paths with specific sequences of properties. Further, the traversal is often only to a depth of 2 or 3, since nodes that are farther removed become irrelevant to the question pretty quickly. This can be expressed as a few rounds of simple queries (one for each step) or an SQL join.
Eliminating the need for a separate graph database makes it easier to use knowledge graphs. Additionally, using Astra DB or Apache Cassandra simplifies transactional writes to both the graph and other data stored in the same place, and likely scales better. That overhead would only be worthwhile if you were planning to generate and execute graph queries, using Gremlin or Cypher or something similar.
But this is simply overkill for retrieving the sub-knowledge graph, and it opens the door for a host of other problems, such as queries that go off the rails in terms of performance.
This traversal is easy to implement in Python. The full code to implement this (both synchronously and asynchronously) using CQL and the Cassandra Driver can be found in the
def fetch_relation(tg: asyncio.TaskGroup, depth: int, source: Node) -> AsyncPagedQuery:
paged_query = AsyncPagedQuery(
depth, session.execute_async(query, (source.name, source.type))
)
return tg.create_task(paged_query.next())
results = set()
async with asyncio.TaskGroup() as tg:
if isinstance(start, Node):
start = [start]
discovered = {t: 0 for t in start}
pending = {fetch_relation(tg, 1, source) for source in start}
while pending:
done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_COMPLETED)
for future in done:
depth, relations, more = future.result()
for relation in relations:
results.add(relation)
# Schedule the future for more results from the same query.
if more is not None:
pending.add(tg.create_task(more.next()))
# Schedule futures for the next step.
if depth < steps:
# We've found a path of length `depth` to each of the targets.
# We need to update `discovered` to include the shortest path.
# And build `to_visit` to be all of the targets for which this is
# the new shortest path.
to_visit = set()
for r in relations:
previous = discovered.get(r.target, steps + 1)
if depth < previous:
discovered[r.target] = depth
to_visit.add(r.target)
for source in to_visit:
pending.add(fetch_relation(tg, depth + 1, source))
return results
Conclusion
This article showed how to build and use knowledge graph extraction and retrieval for question answering. The key takeaway is that you don’t need a graph database with a graph query language like Gremlin or Cypher to do this today. A great database like Astra that efficiently handles many queries in parallel can already handle this.
In fact, you could just write a simple sequence of queries to retrieve the sub-knowledge graph needed for answering a specific query. This keeps your architecture simple (no added dependencies) and lets you
We’ve used these same ideas to implement GraphRAG patterns for Cassandra and Astra DB. We’re going to contribute them to LangChain and work on bringing other improvements to the use of knowledge graphs with LLMs in the future!
By Ben Chambers, DataStax