
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jinrui Yang, School of Computing & Information Systems, The University of Melbourne (Email: jinruiy@student.unimelb.edu.au);
(2) Timothy Baldwin, School of Computing & Information Systems, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence, UAE (Email: (tbaldwin,trevor.cohn)@unimelb.edu.au);
(3) Trevor Cohn, School of Computing & Information Systems, The University of Melbourne.
Table of Links
Conclusion, Limitations, Ethics Statement, Acknowledgements, References, and Appendix
4 Experiments and Findings
We conduct preliminary experiments in both one-vs-one and one-vs-many settings, as described above.
Methods We base our experiments on BM25 with default settings (k1 = 0.9 and b = 0.4), a popular traditional information retrieval baseline. Our implementation is based on Pyserini (Lin et al., 2021), which is built upon Lucene (Yang et al., 2017). Notably, the latest LUCENE 8.5.1 API offers language-specific tokenizers, [6] covering 19 out of the 24 languages present in Multi-EuP. For the remaining languages — namely Polish (PL), Croatian (HR), Slovak (SK), Slovenian (SL), and Maltese (MT) — we use a whitespace tokenizer.
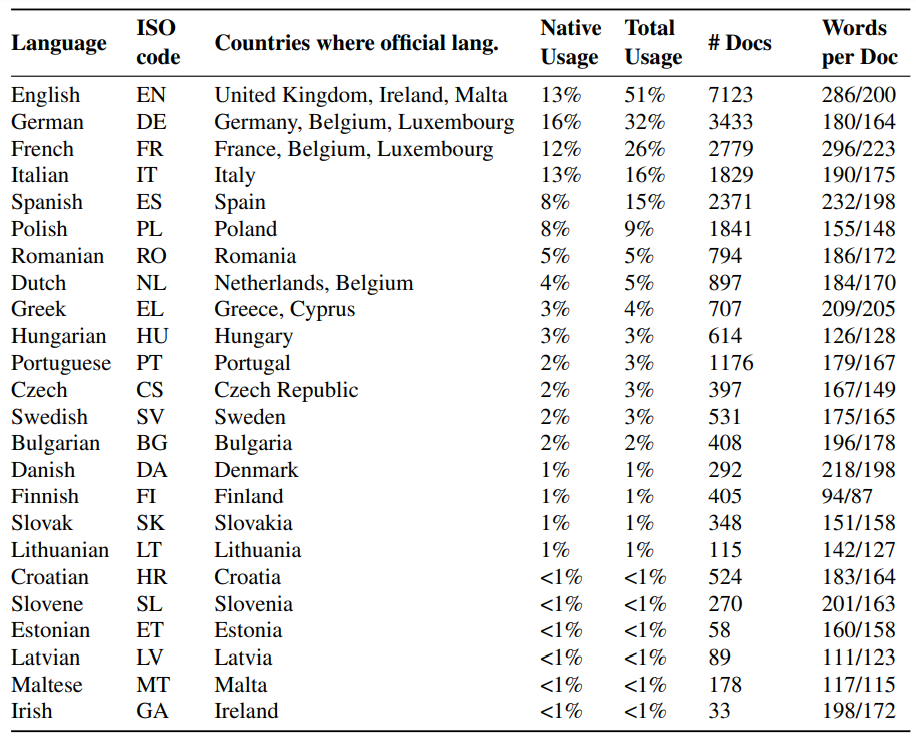

MRR@k denotes MRR computed at a depth of k results. Note that the higher the number the better, and that a perfect retriever achieves an MRR of 1 (assuming every query has at least one relevant document). The choice of setting k = 100 aligns with prior endeavors over MS MARCO (Nguyen et al., 2016).
4.1 Monolingual IR (one-vs-one)
Experimental Setup We first present results over Multi-EuP in a monolingual setting across the 24 different languages. Specifically, we evaluate single-language queries against documents in the same language. In this configuration, we partitioned our original collection of 22K documents into 24 distinct language-specific sub-collections. Table 2 presents the results broken down across languages.
Results and Findings Table 2 presents the MRR@100 results for BM25 on Multi-EuP. There are two high-level findings:
First, Multi-EuP is a relatively easy benchmark for monolingual information retrieval, as the MRR@100 is always around 40 or greater (meaning that the first relevant document is in the top-3 results on average). Indeed, the average MRR across the 24 test languages is 49.61. While direct comparison is not possible, it is noteworthy that for Mr. TYDI, the average MRR is 32.1 across 11 languages. Part of this difference can be attributed to the fact that our relevance judgments are not as sparse as theirs.
Second, similar to Mr. TYDI, direct comparison of absolute scores between languages is not meaningful in a monolingual setting, as the document collection size differs.
4.2 Multilingual IR (one-vs-many)
Experimental Setup In contrast to Mr. TYDI (Zhang et al., 2021), Multi-EuP supports one-vs-many retrieval, and allows us to systematically explore the effect of querying the same document collection with the same set of topics in different languages. This is because we have translations of the topics in all languages, documents span multiple languages, and judgments are cross-lingual (e.g., English queries potentially yield relevant Polish documents). For this experiment, we use the default whitespace tokenizer in the Pyserini library.
Results and Findings Table 2 presents the MRR results for BM25 for multilingual information retrieval on 100 topics from the Multi-EuP test set. It’s worth noting that these topics have translationequivalent content in the different languages. Consequently, the one-vs-many approach allows us to analyze language bias. We made several key observations:
First, unsurprisingly, having more relevance judgments tends to improve ranking accuracy. Therefore, when comparing English topics with other languages, English exhibits notably better MRR performance.
Second, despite there being consistency in the topics, document collection, and relevance judgments, there is a significant disparity in MRR scores across languages, an effect we investigate further in the next section.
[6] Provided by the Anaylzer package in LUCENE. https: //lucene.apache.org/core/8_5_1/analyzers-common/ index.html