
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Ghazaleh H. Torbati, Max Planck Institute for Informatics Saarbrucken, Germany & ghazaleh@mpi-inf.mpg.de;
(2) Andrew Yates, University of Amsterdam Amsterdam, Netherlands & a.c.yates@uva.nl;
(3) Anna Tigunova, Max Planck Institute for Informatics Saarbrucken, Germany & tigunova@mpi-inf.mpg.de;
(4) Gerhard Weikum, Max Planck Institute for Informatics Saarbrucken, Germany & weikum@mpi-inf.mpg.de.
Table of Links
- Abstract and Introduction
- Related Work
- Methodology
- Experimental Design
- Experimental Results
- Conclusion
- Ethics Statement and References
III. METHODOLOGY
A. System Architecture
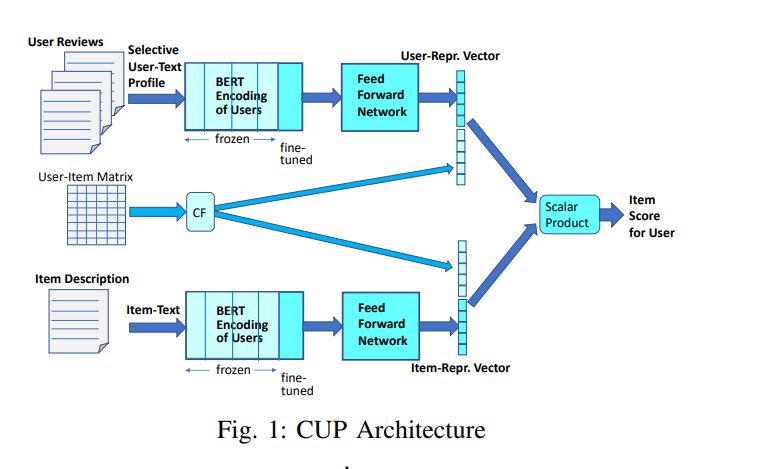
The CUP framework is based on a two-tower architecture for representation learning (one ”tower” for users, the other for items, following the prevalent architecture in neural information retrieval with query and document/passage encodings). The two towers are jointly trained, coupled by the shared loss function and ground truth. Figure 1 shows a pictorial overview.
User reviews and items descriptions are fed into BERT followed by a feed-forward network to learn latent representations. Downstream, the vectors are simply compared by a dot product for scores that indicate whether the user likes an item or not. Importantly, unlike prior works, we allow the top-most layer of BERT itself to be fine-tuned as part of the end-to-end training process.
The per-item text usually comprises book titles, tags like categories or genre labels, which can be coarse (e.g., “thriller”) or fine-grained (e.g., “Scandinavian crime noir”), and a short description of the book contents. The per-user text can comprise the titles and tags of her training-set books and the entirety of her review texts, which vary widely in length and informativeness, hence the need for smart text selection.
In the following, we present the CUP training procedure in Subsection III-B, the test/deployment-time inference in Subsection III-C, the judicious selection of input text snippets in Subsection III-D, and the selection of negative training samples in Subsection III-E.
B. Training

Another optional mechanism is to process multiple chunks of bounded-length text, which could be of interest for long user reviews. In this case, the per-user representations are learned for each chunk, and there is an additional max-pooling step between the FFN and the dot product, to combine the per-chunk vectors. We use this option for comparison in experiments. As it incurs m times higher computational and energy costs, with m being the number of chunks, we do not favor it.
A user-item pair is classified with score calculated by
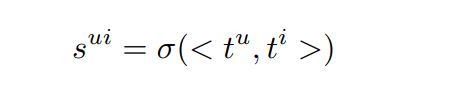
with <, > denoting dot product and σ for the sigmoid function. We use the Adam optimizer to minimize the binary cross entropy loss between predicted labels and the ground truth with sampled negatives. During training we update the topmost layer of BERT, which allows end-to-end training of all components. This is an important difference to earlier works with similar architectures, which use frozen BERT to encode user and item representations.
C. Inference
Prediction for Ranking. At test time, a prediction is made for user-item pairs. We encode the item description by running it through the trained network, and we compare it to the already learned user vector, which is based on the user’s training-time reviews (none for the given test item). The scores for different test items, computed by the final dot product, yield the ranking of the candidate items. This is a very efficient computation, following established practice in neural information retrieval [37].
Search-based Recommendation. In a deployed system (as opposed to lab experiments with test samples), a typical usage mode would be search-based re-ranking: a user provides context with a tag-based query or an example of a specific liked item, which can be thought of as query-by-example. The user’s expectation is to see a ranked list of recommended items that are similar to her positive sample (as opposed to recommendations from all kinds of categories). The system achieves this by first computing approximate matches to the query item (i.e., similarity-search neighbors), and then re-ranking a shortlist of say top-100 candidates. The CUP framework supports this mode, by using a light-weight BM25 retrieval model, querying all unlabeled items with the category and textual description of the positive point at hand, and keeping the top-100 highest scoring matches.
D. Coping with Long and Noisy Texts
For constructing user profiles from text, the simplest idea would be to concatenate all available reviews into a long token sequence. Two problems arise, though. User reviews are a noisy mix of descriptive elements (e.g., “the unusual murder weapon”), sentiment expressions (e.g., “it was fun to read”) and personal but irrelevant statements (e.g., “I read only on weekends”). Only the first aspect is helpful for content-based profiling (as the sentiment is already captured by the fact that the user likes the book). Second, the entirety of user-provided text can be too long to be fully digested by the Transformer. Even when it would fit into the token budget, the computational and energy cost is quadratic in the number of input tokens. Therefore, we tightly limit the tokens for each user’s text profile to 128, and devise a suite of light-weight techniques for judiciously selecting the most informative pieces.
Variants of our methodology are to create concise profiles by generative language models upfront (e.g., using T5 or ChatGPT), or to digest multiple chunks of text with downstream aggregation by max-pooling or averaging. We include these techniques in our experimental comparisons, but emphasize that both of these alternatives have much higher computational cost and climate footprint.
Our techniques for selecting the most informative parts of user reviews to construct concise profiles, are as follows:
• Weighted Phrases: selected unigrams, bigrams or trigrams, ordered by descending tf-idf weights, where tf is the frequency of the phrase in all of the given user’s reviews, and idf is pre-computed on Google books n-grams to capture informativeness.
• Weighted Sentences: selected sentences, ordered by descending idf weights, where a sentence’s total weight is the sum of the per-word idf weights normalized by sentence length.
• Similar Sentences: selected sentences, ordered by descending similarity scores computed via Sentence-BERT [38] for comparing the user-review sentences against the sentences of the item description. To ensure that the selected set is not dominated by a single item, the sentences are picked from different items in a round-robin manner.
• ChatGPT-generated Profiles: feeding all reviews of a user, in large chunks, into ChatGPT and instructing it to characterize the user’s book interests with a few short keyphrases. The output size is limited per chunk with a total budget of 128 tokens, to enforce concise profiles.
• T5-generated Keywords: using a T5 model fine-tuned for keyword generation, to cast each user’s review text into a set of keywords, concatenated to create the profile.
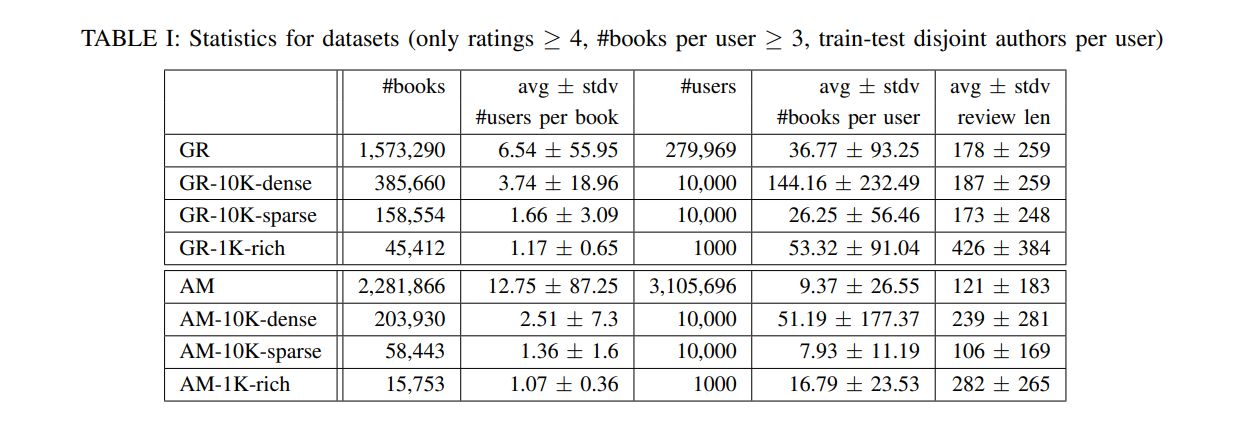
We give examples of selected profile constructions for a Goodreads and an Amazon user in Table VII. An online demo of the CUP framework is accessible on our website[2].
E. Coping with Unlabeled Data
A challenge for training in the data-poor regime is how to handle the extreme skew between positive samples and unlabeled data points for sparse users. The crux in many recommender applications is that there are extremely few, if any, explicitly negative samples, such as books rated with low marks. This holds also for the datasets in this work.
Therefore, we introduce and experiment with two different techniques to construct negative training samples from unlabeled data:
• Uniform random samples. Under the closed world assumption (CWA), aka Selected Completely At Random, negative training points are sample uniformly from all unlabeled data. This is the baseline technique, widely used in prior works.
• Weighted pos-neg samples. Prior works on PU learning [39], with positive and unlabeled data and without explicitly negative samples, is largely based on treating unlabeled points as pairs of samples, one positive and one negative with fractional weights. The weights can be based on (learned estimates of) class priors, but the extreme skew in our data renders these techniques ineffective. Instead we leverage the fact that relatedness measures between item pairs can be derived from tagging features or interaction data. We compute item-item relatedness via basic matrix factorization of the user-item matrix for the entire dataset. The relatedness of two items is set to the scalar product between their latent vectors, re-scaled for normalization between 0 and 1. Then, each originally unlabeled sample is cloned, with one instance positive with weight proportional to its average relatedness to the user’s explicitly positive points. The negative clone’s weight is set to the complement.
[2] https://sirup.mpi-inf.mpg.de/