
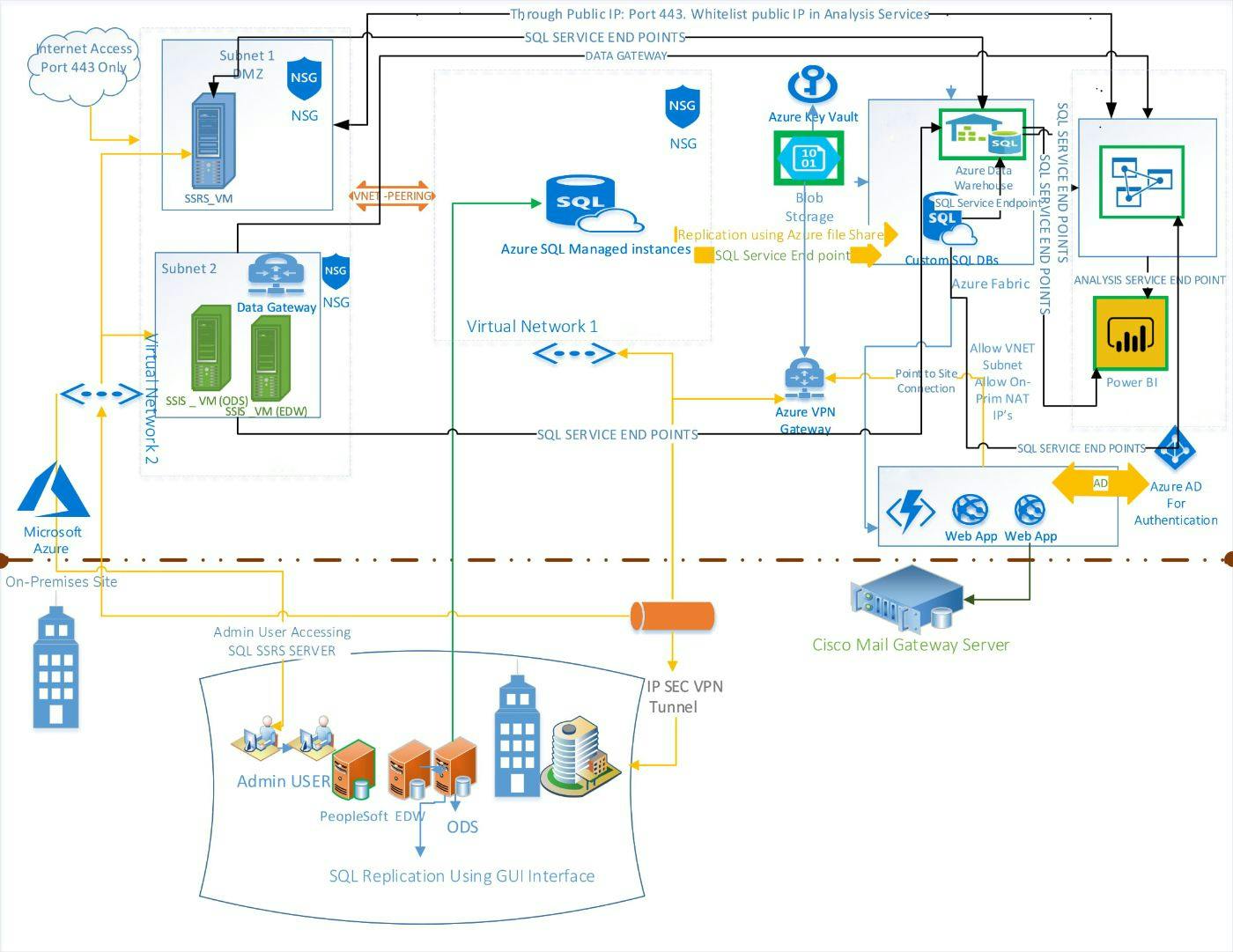
Today, many groups see the worth of moving their data setups from their own sites to the cloud. Azure, made by Microsoft, offers a strong and wide-reaching stage for data jobs. This write-up aims to give a clear and comprehensive guide for moving a data system, built on Cloudera, over to Azure. We will look into the main points to think about, the problems one might face, and the best ways to go about this move.
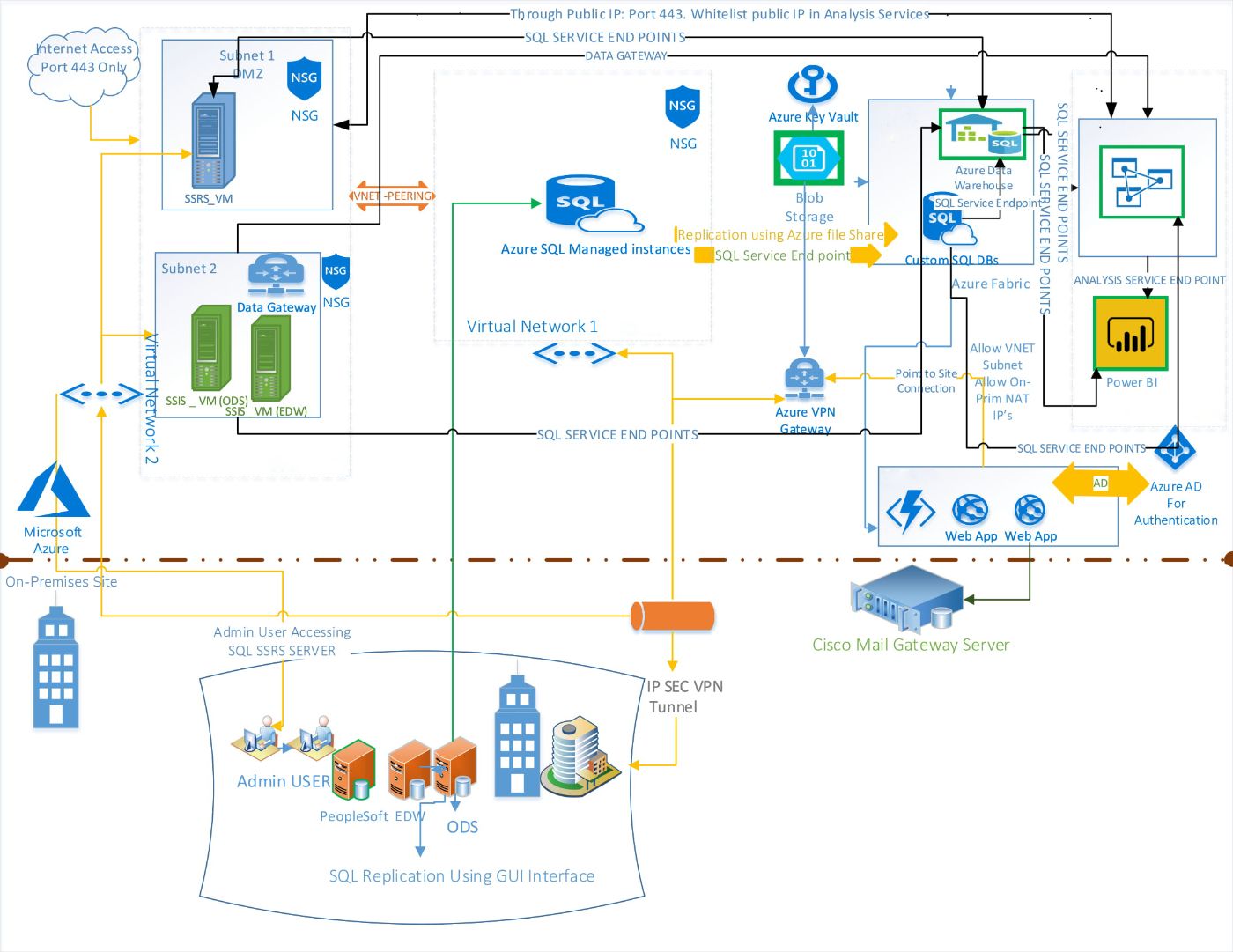
Key Considerations for Migrating an On-Premise Data Pipeline to Azure:
-
Data Assessment and Planning: Start by looking closely at what you have. Know your data sources, steps, who needs what, and how big it all is. This helps spot any big issues or special needs early. Make a plan that says who does what, when, and how. Think about backup plans too.
-
Pick the RIght Azure Tools: Azure has many tools that can do what your on-site Cloudera does. Look at options like Azure Data Lake Storage for keeping lots of data safe, Azure Databricks for working with big data, Azure SQL Database for data tables, and Azure HDInsight for Hadoop setups. Make sure your software and tools play nice with Azure.
-
Security and Compliance: Moving data means keeping it safe is a top priority. Azure has strong security features and meets many compliance standards. Look into using Azure Active Directory for managing who can get in, Azure Key Vault for keeping encryption keys safe, and Azure Security Center for watching for threats. Also, make sure you're keeping up with laws and standards in your field.
-
Data Transfer and Migration Strategy: Develop a well-defined strategy for transferring and migrating your data from the on-premise environment to Azure. Evaluate the data volume, velocity, and variety to determine the most suitable data transfer methods. Azure Data Factory, Azure Data Box, Azure ExpressRoute, or third-party tools can be utilized for data transfer. Prioritize critical data and plan the migration in stages or parallel streams to minimize downtime. Consider data encryption, integrity checks, and data validation during the migration process to ensure data consistency and accuracy in the Azure environment.
-
Network Connectivity and Bandwidth Considerations: Assess the network connectivity between your on-premise environment and Azure to determine the available bandwidth and latency. Consider the network limitations and potential bottlenecks that may impact data transfer and application performance. Evaluate Azure’s networking capabilities, such as Azure Virtual Network and ExpressRoute, to establish secure and high-performance connections between on-premise and Azure environments. Optimize network configurations and consider network optimization techniques, such as data compression, to minimize transfer time and reduce network bandwidth consumption.
-
Skills and Training: Evaluate your team’s skill sets and familiarity with Azure services. Identify any gaps and provide training or seek external expertise where necessary. Familiarize your team with Azure’s tools, services, and best practices to ensure a smooth transition and efficient management of the migrated data pipeline.
By considering these key aspects during the migration process, organizations can effectively plan and execute the migration of their on-premise data pipelines to Azure. Thorough evaluation, meticulous planning, and addressing security and compliance requirements will ensure a successful and seamless transition, allowing organizations to leverage the scalability, flexibility, and advanced features offered by Azure’s cloud platform.
Migration approaches
The following diagram shows three approaches to migrating Hadoop applications:
The diagram above shows three approaches to migrating Hadoop applications (Microsoft Azure)
The approaches are:
- Replatform by using Azure PaaS: For more information, see Modernize by using Azure Synapse Analytics and Databricks.
- Lift and shift to HDInsight: For more information, see Lift and shift to HDInsight.
- Lift and shift to IaaS: For more information, see Lift and shift to Azure infrastructure as a service (IaaS).
Steps for Migrating an On-Premise Data Pipeline to Azure:
-
Infrastructure Provisioning: The first step in migrating an on-premise data pipeline to Azure is to provision the necessary infrastructure. Azure offers a wide range of services and resources to replicate your on-premise environment. Provision virtual machines, storage accounts, and networking components based on your workload requirements. You can use Azure Resource Manager templates or Infrastructure as Code tools like Azure Resource Manager or Terraform to define and provision your infrastructure in a repeatable and automated manner. Ensure that you align your Azure infrastructure with the requirements of your on-premise data pipeline.
-
Data Migration: Once the infrastructure is provisioned, it’s time to migrate your data from the on-premise environment to Azure. Evaluate the volume and size of your data to determine the most suitable migration approach. For large-scale data transfers, Azure Data Factory can be used to orchestrate the movement of data from on-premise storage systems to Azure storage services such as Azure Data Lake Storage or Azure Blob Storage. For smaller datasets, you can use tools like AzCopy or Azure Import/Export service. Pay attention to data integrity and consistency during the migration process, verifying that the data in Azure matches the on-premise source.
-
Configuration and Integration: After the data migration, configure and integrate the necessary components of your data pipeline in Azure. Set up the relevant Azure services to replicate the functionalities of your on-premise environment. For example, you can deploy Azure HDInsight clusters for Hadoop or Spark processing, use Azure Databricks for advanced analytics, or leverage Azure SQL Database for relational data storage. Update application configurations, connections, and credentials to connect with the Azure resources. Utilize data orchestration tools like Apache Airflow or Azure Data Factory to manage the workflows, schedule data processing tasks, and ensure smooth data movement within the pipeline.
-
Testing and Validation: Once the configuration and integration are complete, thoroughly test and validate your migrated data pipeline in the Azure environment. Execute end-to-end tests to ensure that data ingestion, processing, and storage functionalities are working as expected. Validate data accuracy, transformations, and output results against the expected outcomes. Conduct performance testing to ensure that the pipeline meets the required performance benchmarks. Identify and resolve any issues or discrepancies during this testing phase to guarantee the reliability and efficiency of the migrated pipeline.
-
Deployment and Go-Live: With successful testing and validation, it’s time to deploy and go live with your migrated data pipeline in Azure. Coordinate with your team to plan the cutover from the on-premise environment to Azure, ensuring minimal disruption to ongoing operations. Update DNS configurations, network settings, and any necessary firewall rules to redirect traffic to the Azure environment. Monitor the initial operation of the migrated pipeline closely to identify and address any issues that may arise during the go-live phase.
-
Ongoing Monitoring and Optimization: After the migration is complete, it is crucial to continuously monitor and optimize your migrated data pipeline in Azure. Leverage Azure’s monitoring services such as Azure Monitor, Azure Log Analytics, and Azure Advisor to gain insights into the pipeline’s performance, resource utilization, and potential bottlenecks. Fine-tune configurations, scale resources as needed, and optimize data processing workflows for better performance and cost efficiency. Regularly review and update security measures, backup strategies, and disaster recovery plans to ensure data resilience and maintain business continuity.
By following these steps, organizations can successfully migrate their on-premise data pipelines to Azure. Thorough infrastructure provisioning, seamless data migration, configuration and integration, comprehensive testing, and ongoing monitoring and optimization are key to achieving a smooth and efficient transition. The result is a robust and scalable data pipeline in Azure, empowering organizations to leverage the full potential of cloud-based data processing and analytics capabilities.
Conclusion
Migrating an on-premise data pipeline to Azure requires careful planning, execution, and ongoing optimization to ensure a successful and efficient transition. By following the steps outlined in this guide, organizations can navigate the migration process with confidence and unlock the benefits of Azure’s scalable and flexible cloud platform.
To further enhance the planning and execution of the migration, consider exploring the following ideas:
-
Pilot and Incremental Migration: Consider conducting a pilot migration or adopting an incremental migration approach. Start with a smaller subset of data and workflows to test and validate the migration process. This allows for early identification of challenges, fine-tuning of the migration strategy, and building confidence before migrating the entire data pipeline.
-
Performance and Scalability Considerations: Evaluate the performance and scalability requirements of your data pipeline in Azure. Consider factors such as data volume growth, peak usage periods, and anticipated workloads. Design and provision Azure resources accordingly to ensure optimal performance and scalability, taking advantage of Azure’s auto-scaling capabilities when necessary.
-
Data Governance and Compliance: Take the opportunity to reassess and enhance your data governance and compliance practices during the migration process. Consider implementing Azure’s built-in data governance features, such as Azure Purview, to improve data discovery, classification, and compliance with regulations like GDPR or HIPAA. Leverage Azure Policy and Azure Sentinel for enhanced security monitoring and threat detection.
-
Cost Optimization: Explore cost optimization strategies to maximize the cost efficiency of your migrated data pipeline in Azure. Utilize Azure Cost Management and Azure Advisor to monitor and optimize resource usage. Consider using Azure Reserved Instances or Azure Spot VMs for cost savings. Regularly review and refine resource allocations based on usage patterns to minimize unnecessary costs.
-
Data Backup and Disaster Recovery: Ensure robust data backup and disaster recovery strategies are in place for your migrated data pipeline. Leverage Azure services such as Azure Backup and Azure Site Recovery to automate data backups, replication, and failover. Regularly test disaster recovery plans to ensure data resiliency and business continuity.
-
Collaboration and Training: Foster collaboration among stakeholders involved in the migration process, including infrastructure teams, data engineers, and application owners. Encourage knowledge sharing, cross-training, and collaboration to facilitate a smooth transition. Invest in training and upskilling to empower your team to leverage Azure’s services effectively.
By exploring these ideas and incorporating them into your migration plan, you can further improve the efficiency and effectiveness of migrating your on-premise data pipeline to Azure. Remember to regularly review and optimize the migrated pipeline, adapting to evolving business needs and taking advantage of new Azure features and services.
With careful planning, seamless execution, ongoing optimization, and a focus on continuous improvement, organizations can successfully migrate their on-premise data pipelines to Azure, unlocking the benefits of scalability, flexibility, and advanced data processing capabilities offered by the cloud. Embrace the power of Azure and empower your data-driven initiatives to thrive in the digital era.