
Language models (LMs) represent a highly versatile category of technology, processing text inputs to generate textual outputs. Contemporary research has illuminated that this adaptable text-to-text framework can be harnessed to address a myriad of tasks without necessitating task-specific adjustments (i.e., absent fine-tuning or architectural changes) through the use of prompting methods to enable precise zero and few-shot inference. In essence, LMs are initially trained on extensive, unlabelled text corpora (guided by a language modeling objective), after which the LMs are directed via textual prompts to resolve specific problems, thereby allowing the pre-trained model to be efficiently repurposed for varied applications.
Despite the immense promise of LMs as task-neutral foundation models, initial endeavours to apply pre-trained LMs to downstream tasks (e.g., GPT and GPT-2 [4, 5]) encountered significant challenges. This overview will explore how recent advancements have improved upon these preliminary efforts, leading to LMs that deliver significantly enhanced task-neutral performance. A critical discovery in this research trajectory is the enhanced capability of LMs as they are scaled up.
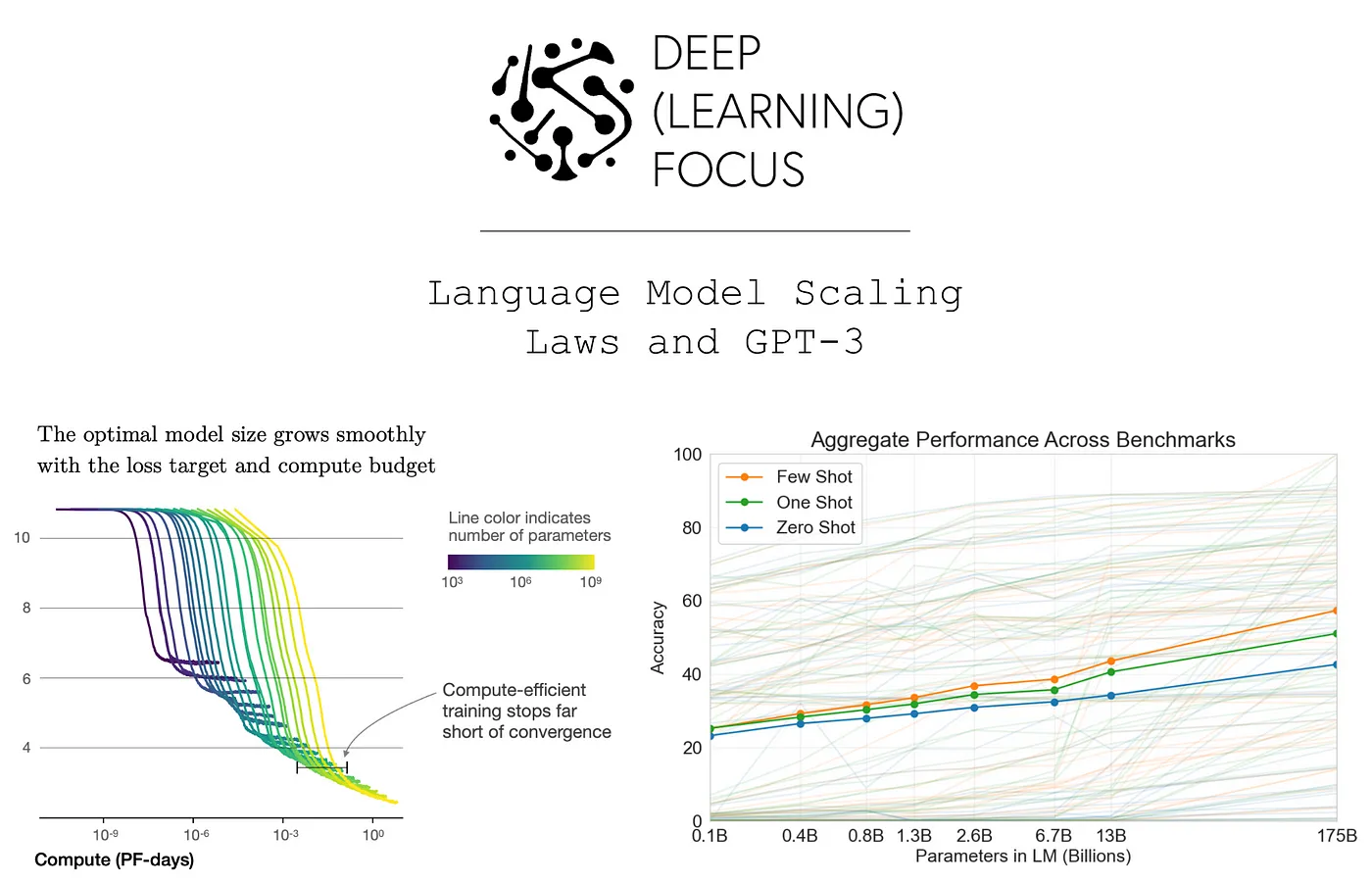
(from [1] and [2])
More detailed examination reveals that large LMs (LLMs) are (i) more sample-efficient compared to their smaller counterparts and (ii) exhibit greater proficiency in task-neutral transfer to downstream applications. Notably, the performance of these LLMs demonstrates predictable patterns relative to various parameters (e.g., model scale and training data volume). This empirical evidence has culminated in the development of GPT-3, a colossal LLM with 175 billion parameters, which not only surpasses its predecessors in task-neutral performance but also exceeds contemporary, supervised deep learning approaches in certain domains.
Background Key concepts necessary for understanding LMs have been discussed in my previous posts, including the language modeling objective, the architecture of decoder-only transformer models, and their integration to forge robust foundation models. For a more thorough understanding, refer to the provided link.
I will offer a succinct overview of these concepts here, while also delineating a few additional notions pertinent to comprehending LLMs like GPT-3.
Language modeling at a glance Modern LMs utilize standard pre-training methods to tackle a broad spectrum of tasks without subsequent modifications (i.e., no architectural adjustments, fine-tuning, etc.). Employing a voluminous corpus of unlabelled text, we pre-train our LM with a language modeling objective that (i) extracts a text sample from our corpus and (ii) attempts to predict the succeeding word. This represents a form of self-supervised learning, where the correct next word can always be verified by examining the data in our corpus.
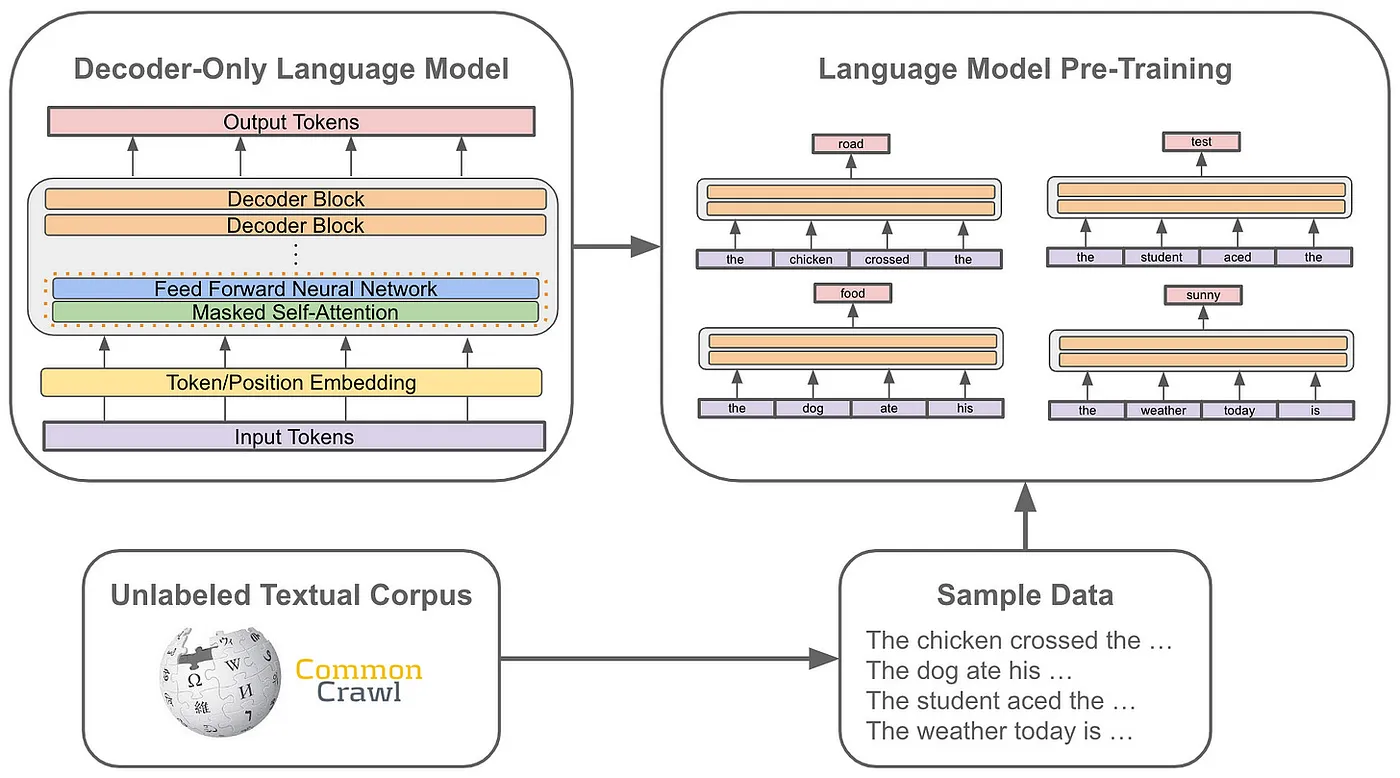
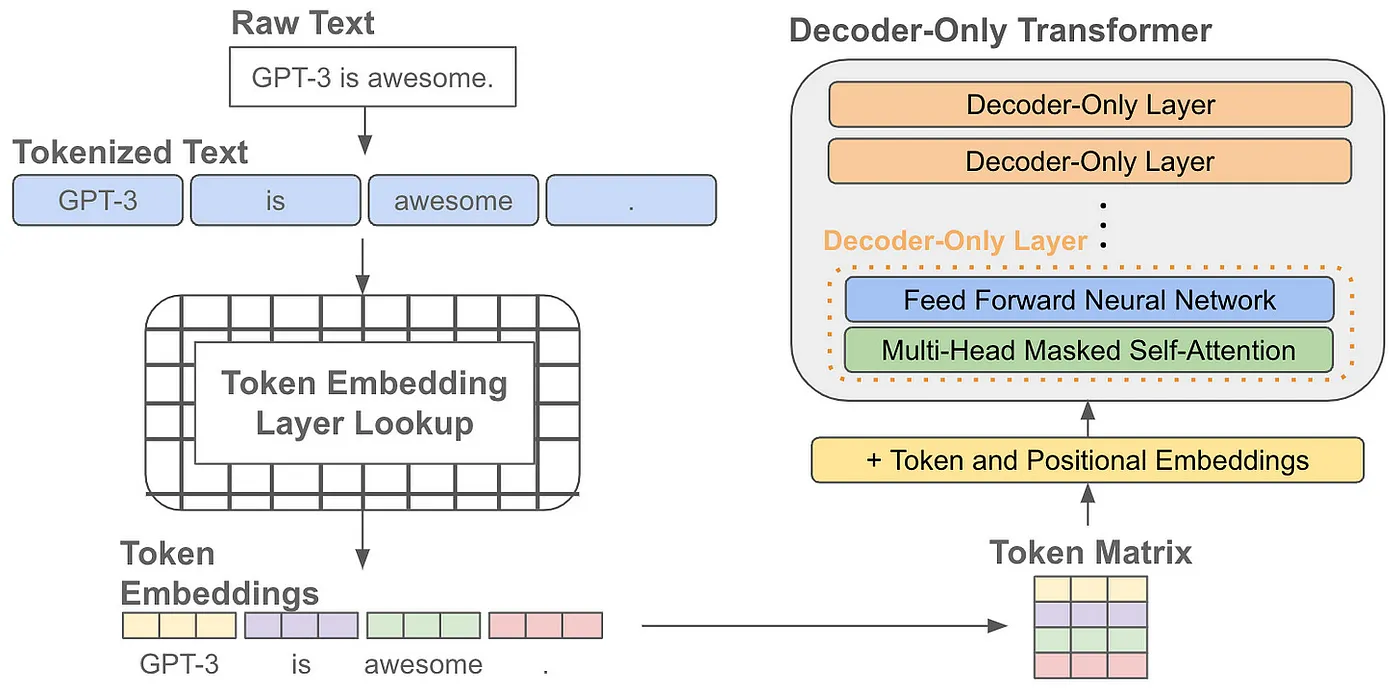
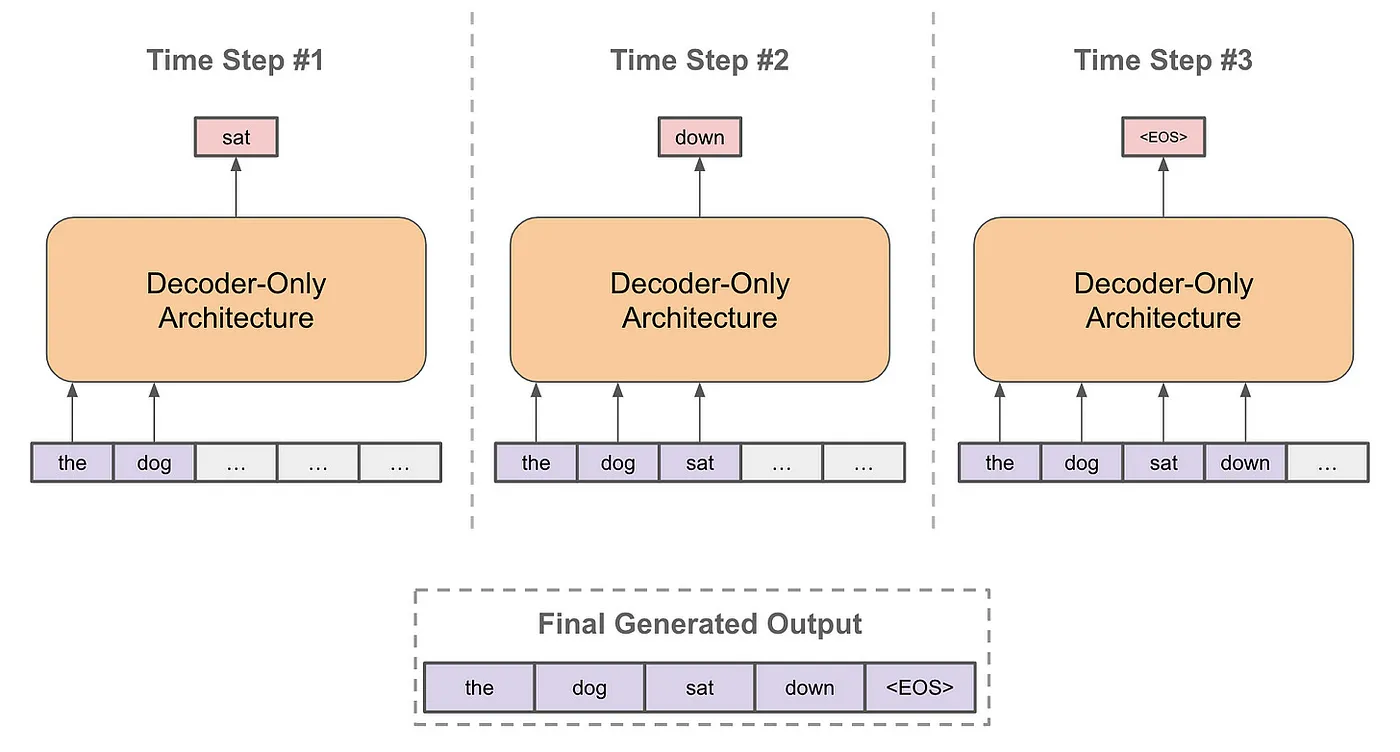
Architecture Modern LMs employ decoder-only transformer architectures, which apply a series of layers that include masked self-attention and forward transformations to the input. Masked self-attention, as opposed to bidirectional self-attention, precludes the model from 'peeking ahead' in a sequence to predict the subsequent word.
Beyond these decoder-only layers, the LM architecture encompasses embedding layers that store vectors for all potential tokens within a predefined vocabulary size. Through these embedding layers, raw text is transformed into a matrix that the model can process, achieved by:
- Tokenizing raw text into discrete tokens (i.e., words or sub-words),
- Retrieving the corresponding embedding vector for each token,
- Concatenating these token embeddings to form a matrix or sequence of token vectors,
- Integrating position (and other) embeddings to each token vector.
Adaptation By pre-training LMs over expansive text corpora, we obtain models capable of accurately predicting the next token within a given token sequence. However, to utilize these models for language understanding tasks such as sentence classification and language translation, we do not modify the LM. Instead, we leverage the model’s inherent generic text-to-text input-output structure by supplying textual "prompts," such as:
“Translate this sentence to English: <sentence> =>” “Summarize the following document: <document> =>”.
With these problem-solving prompts, a proficient LM should yield a textual sequence that addresses the query effectively. For scenarios requiring a selection from a predetermined set of responses (e.g., multiple choice or classification), the LM can be used to assess the likelihood of generating each potential response and select the most probable outcome.
Main takeaway The essence of modern LLMs lies in utilizing language model pre-training as a mechanism to develop generic foundation models capable of resolving diverse challenges without the need for adaptation or fine-tuning. While previous LMs like GPT and GPT-2 [4, 5] demonstrated inferior performance relative to tailored or supervised language understanding methods, this learning paradigm holds considerable promise and—as evidenced by GPT-3—can yield impressive results when the underlying LM is substantially enlarged.
Power Laws
In this overview, we will frequently refer to the concept of power laws. To illustrate, consider a statement from a research paper:
"The LM’s test loss demonstrates a power law dependency on the number of model parameters."
This assertion establishes a correlation between two variables—the loss and the number of model parameters—wherein adjustments to one variable induce proportionate, scale-independent alterations in the other.
For clarity, a power law is mathematically expressed as follows.
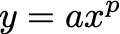
In this equation, x and y represent the variables under examination, while a and p influence the power law's shape and dynamics. When this power law (with a = 1, p = 0.5, and 0 < x, y < 1) is graphed, converting both axes to a logarithmic scale reveals a distinct linear trend, characteristic of power laws.
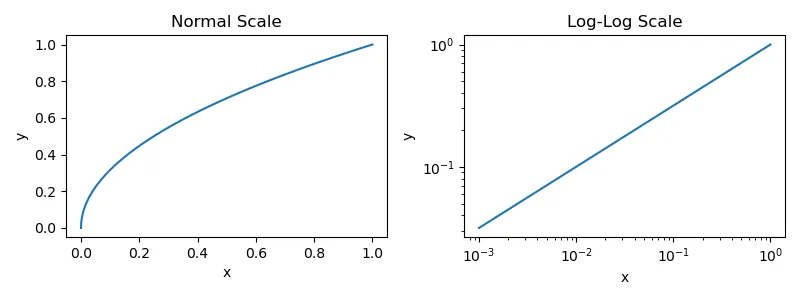
Power laws describe how one variable scales as a power of another. Our discussions will include an inverse version of a power law, represented as:
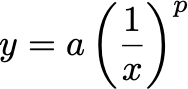
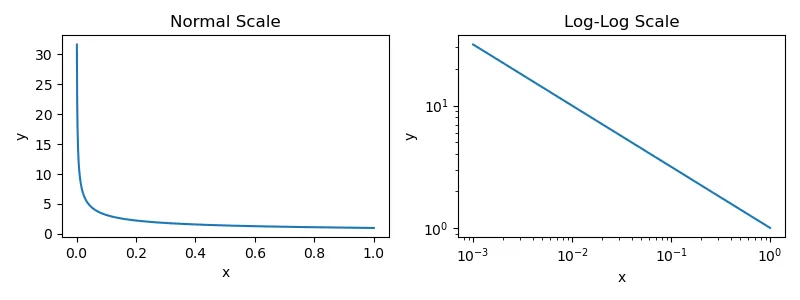
This equation employs a negative exponent for p, producing a graph where one variable decreases as the other increases.
In our analysis of LMs, we observe that the LM loss decreases in accordance with a power law across various dimensions, such as model or dataset size. Further elaboration on this will follow in subsequent sections.
Additional Useful Concepts
In addition to the foundational principles of language modeling, there are several ancillary concepts that will be beneficial to understand moving forward.
Distributed Training The primary focus of the papers discussed in this overview is on scaling models like GPT and GPT-2 [4, 5]. As models grow in complexity, training them becomes increasingly challenging due to heightened computational and memory demands. Distributed training methods, which utilize additional hardware resources (e.g., more servers/GPUs), facilitate the scalability of large training operations.
There are various strategies for distributing the training workload of neural networks. One such strategy is data parallel training, which involves:
- Taking a large mini-batch,
- Dividing it into smaller sub-batches,
- Performing computations for each sub-batch in parallel across different GPUs,
- Consolidating the results from each GPU to update the central model.
This method enhances training efficiency by parallelizing computations across multiple GPUs.
Alternatively, model-parallel training divides the model itself across several GPUs. For instance, each layer—or even sub-components of each layer—might be allocated to different GPUs. This distribution allows the forward pass of the training process to occur across multiple devices, enabling the training of larger models and potentially improving efficiency through sophisticated pipelining and parallelization.
For the purposes of this overview, it is important to recognize that leveraging multiple GPUs can make training of large language models (LLMs) more manageable and efficient. Data and model parallel training represent popular techniques in distributed training. There are numerous other strategies and considerations in this field that significantly enhance practical outcomes in deep learning.
Critical Batch Size Utilizing large batches in data parallel training is generally advantageous for computational efficiency. However, excessively large batches may impair model performance and escalate computational costs, requiring more hardware. This phenomenon of diminishing returns becomes evident beyond a certain batch size; see below.
(from [3])
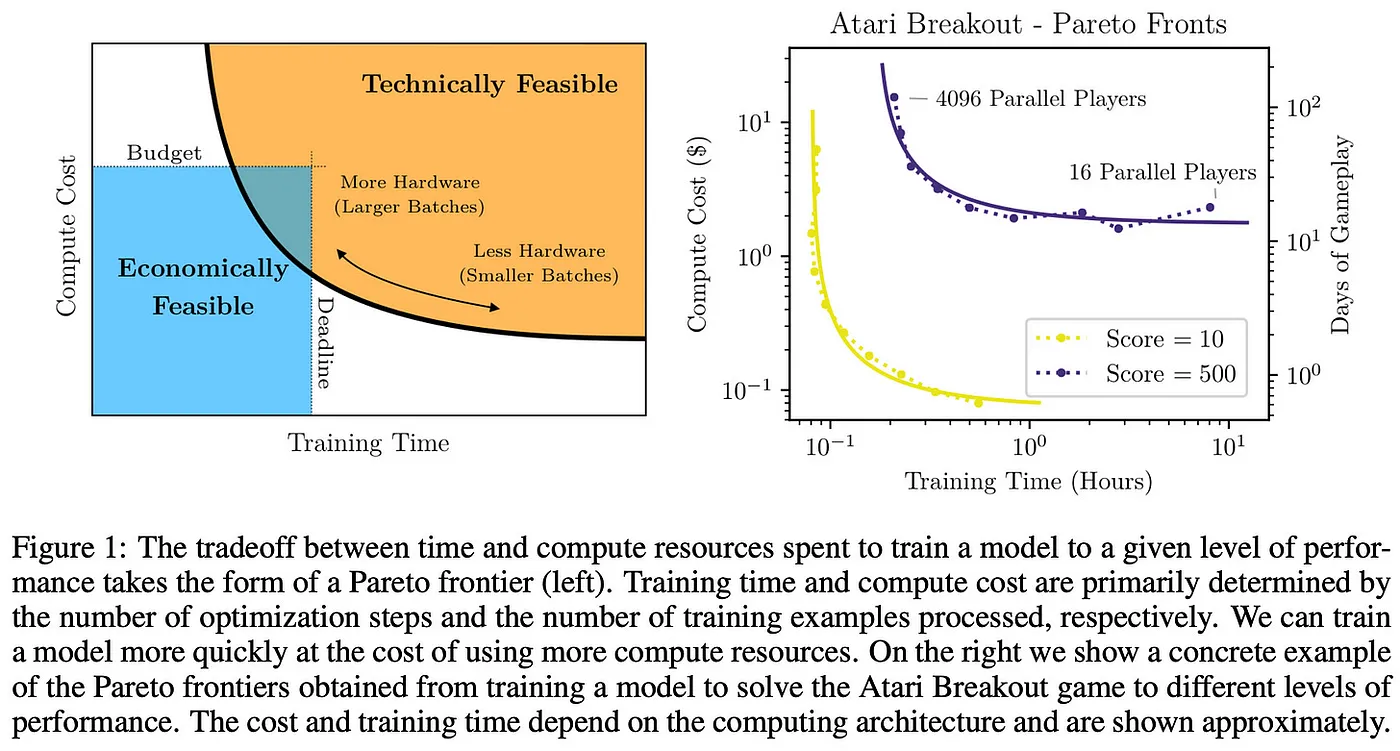
Research has empirically determined the 'critical batch size', a metric that estimates the optimal batch size across various applications. Beyond this critical size, performance gains and computational efficiency start to diminish. As we will explore, some research adopts this critical batch size as a standard for efficient resource utilization during training.
Beam Search Language models generate text sequences in response to prompts through an autoregressive process, predicting each subsequent word based on the previous context. The simplest method continuously selects the most likely next word, but this approach may not yield the optimal overall sequence.
Beam search offers an alternative: instead of choosing the single most probable next word, it selects the top-k most probable options at each step, maintaining a list of potential sequences. At the conclusion of the generation process, the most likely overall sequence from this list is selected.
This method provides a more effective approximation of the best sequence by considering multiple potential continuations at each step, thereby enhancing the quality of the generated text.
Key Insights and Strategic Implications
The foundational goal of GPT models was to develop universal language models capable of addressing a broad spectrum of tasks without necessitating task-specific tuning. This ambition is grounded in the premise that a profound comprehension of language modeling—specifically, the prediction of subsequent words in sequences—can be extrapolated to a variety of applications.
Initially, models such as GPT and GPT-2 did not meet these expectations, delivering subpar performance in task-agnostic settings compared to supervised models. However, this overview has demonstrated that amplifying the scale of these language models (LMs) is an effective strategy for achieving high-performance, task-agnostic language understanding capabilities. This approach culminated in the conceptualization and deployment of GPT-3, an enormously scaled language model (approximately 100 times larger than GPT-2) that significantly outstrips the task-agnostic performance of its predecessors.
Scaling Laws The principle of scaling—enhancing model performance through the augmentation of model size, data volume, and computational resources—has been pivotal. Empirical data suggest that to optimize the efficacy of language model training, it is critical to substantially expand the model's dimensions while moderately increasing the dataset and batch size used during pre-training. This results in models that not only exhibit greater sample efficiency but also improve performance in accordance with power laws related to model size, data volume, and computational investment.
Prospects of Scaling The advent of GPT-3, a model boasting 175 billion parameters, exemplifies the practical validation of these scaling theories. When such a colossal model is pre-trained across extensive text corpora, it demonstrates marked enhancements in task-agnostic, few-shot learning capabilities. Although GPT-3 may still lag behind specialized, supervised methods in certain benchmarks, subsequent studies have convincingly shown that as LLMs increase in size, their capacity for in-context learning also intensifies. Despite GPT-3’s architectural similarities to GPT-2, engineering a model of this magnitude underscores the transformative potential and scalability of foundational language models.
In conclusion, the journey from the initial GPT models to GPT-3 highlights a significant shift in the understanding and application of language models. The scalability of these systems not only advances their performance but also broadens their applicability across a diverse range of language understanding tasks, setting a new benchmark for future developments in the field of artificial intelligence.
Bibliography
[1] Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
[2] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.
[3] McCandlish, Sam, et al. “An empirical model of large-batch training.” arXiv preprint arXiv:1812.06162 (2018).
[4] Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
[5] Radford, Alec, et al. “Language Models are Unsupervised Multitask Learners.”
[6] Child, Rewon, et al. “Generating long sequences with sparse transformers.” arXiv preprint arXiv:1904.10509 (2019).
[7] Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” J. Mach. Learn. Res. 21.140 (2020): 1–67.
[8] Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).